
最新刊期
2024 年 第 29 卷 6 期
2024年第6期


-
 摘要:随着基于对比文本—图像对的预训练(contrastive language-image pre-training,CLIP)方法或者模型、聊天生成预训练转换器(chat generative pre-trained Transformer,ChatGPT)、生成预训练转换器-4(generative pre-trained Transformer-4,GPT-4)等基础大模型的出现,通用人工智能(artificial general intelligence, AGI)的研究得到快速发展。AGI旨在为人工智能系统赋予更强大的执行能力,使其能够自主学习、不断进化,解决各种问题和处理不同的任务,从而在多个领域得到广泛应用。这些基础模型在大规模数据集上进行训练后,能够成功应对多样的下游任务。在这一背景下,Meta公司提出的分割一切模型(segment anything model,SAM)于2023年取得重要突破,在图像分割领域获得了优异的性能,以至于被称为图像分割终结者。其原因之一是,通过SAM数据引擎方法用三阶段采集的、包含1 100万图像和超过10亿掩码的分割一切—十亿(segment anything 1 billion,SA-1B)图像分割数据集,同时保证了掩码的品质和多样性,继续导致在分割领域的突破。在SAM开源后不久,科研人员提出了一系列改进的方法和应用。为了能全面深入了解分割一切模型的发展脉络、优势与不足,本文对SAM的研究进展进行了梳理和综述。首先,从基础模型、数据引擎和数据集等多个方面简要介绍了分割一切模型的背景和核心框架。在此基础上,本文详细梳理了目前分割一切模型的改进方法,包括提高推理速度和增进预测精度两个关键方向。然后,深入探讨分割一切模型在图像处理任务、视频相关任务以及其他领域中的广泛应用。这一部分详细介绍了模型在各种任务和数据类型上的卓越性能,突出其在多个领域的泛用性和发展潜力。最后,对分割一切模型未来的发展方向和潜在应用前景进行了深入分析和讨论。关键词:通用人工智能 (AGI);计算机视觉;图像分割;视觉基础模型;分割一切模型 (SAM);大型语言模型 (LLM)
摘要:随着基于对比文本—图像对的预训练(contrastive language-image pre-training,CLIP)方法或者模型、聊天生成预训练转换器(chat generative pre-trained Transformer,ChatGPT)、生成预训练转换器-4(generative pre-trained Transformer-4,GPT-4)等基础大模型的出现,通用人工智能(artificial general intelligence, AGI)的研究得到快速发展。AGI旨在为人工智能系统赋予更强大的执行能力,使其能够自主学习、不断进化,解决各种问题和处理不同的任务,从而在多个领域得到广泛应用。这些基础模型在大规模数据集上进行训练后,能够成功应对多样的下游任务。在这一背景下,Meta公司提出的分割一切模型(segment anything model,SAM)于2023年取得重要突破,在图像分割领域获得了优异的性能,以至于被称为图像分割终结者。其原因之一是,通过SAM数据引擎方法用三阶段采集的、包含1 100万图像和超过10亿掩码的分割一切—十亿(segment anything 1 billion,SA-1B)图像分割数据集,同时保证了掩码的品质和多样性,继续导致在分割领域的突破。在SAM开源后不久,科研人员提出了一系列改进的方法和应用。为了能全面深入了解分割一切模型的发展脉络、优势与不足,本文对SAM的研究进展进行了梳理和综述。首先,从基础模型、数据引擎和数据集等多个方面简要介绍了分割一切模型的背景和核心框架。在此基础上,本文详细梳理了目前分割一切模型的改进方法,包括提高推理速度和增进预测精度两个关键方向。然后,深入探讨分割一切模型在图像处理任务、视频相关任务以及其他领域中的广泛应用。这一部分详细介绍了模型在各种任务和数据类型上的卓越性能,突出其在多个领域的泛用性和发展潜力。最后,对分割一切模型未来的发展方向和潜在应用前景进行了深入分析和讨论。关键词:通用人工智能 (AGI);计算机视觉;图像分割;视觉基础模型;分割一切模型 (SAM);大型语言模型 (LLM)- 28
- |
- 6
- |
- 0
发布时间:2024-06-27 -
 摘要:生成式基座大模型正在引发人工智能领域的重大变革,在自然语言处理、多模态理解与内容合成等任务展现通用能力。大模型部署于云侧提供通用智能服务,但面临时延大、个性化不足等关键挑战,小模型部署于端侧捕捉个性化场景数据,但存在泛化性不足的难题。大小模型端云协同技术旨在结合大模型通用能力和小模型专用能力,以协同交互方式学习演化进而赋能下游垂直行业场景。本文以大语言模型和多模态大模型为代表,梳理生成式基座大模型的主流架构、典型预训练技术和适配微调等方法,介绍在大模型背景下模型剪枝、模型量化和知识蒸馏等大模型小型化关键技术的发展历史和研究近况,依据模型间协作目的及协同原理异同,提出大小模型协同训练、协同推理和协同规划的协同进化分类方法,概述端云模型双向蒸馏、模块化设计和生成式智能体等系列代表性新技术、新思路。总体而言,本文从生成式基座大模型、大模型小型化技术和大小模型端云协同方式3个方面探讨大小模型协同进化的国际和国内发展现状,对比优势和差距,并从应用前景、模型架构设计、垂直领域模型融合、个性化和安全可信挑战等层面分析基座赋能发展趋势。关键词:生成式大模型;大模型小型化;大小模型协同进化;端云协同进化;生成式智能体;生成式人工智能
摘要:生成式基座大模型正在引发人工智能领域的重大变革,在自然语言处理、多模态理解与内容合成等任务展现通用能力。大模型部署于云侧提供通用智能服务,但面临时延大、个性化不足等关键挑战,小模型部署于端侧捕捉个性化场景数据,但存在泛化性不足的难题。大小模型端云协同技术旨在结合大模型通用能力和小模型专用能力,以协同交互方式学习演化进而赋能下游垂直行业场景。本文以大语言模型和多模态大模型为代表,梳理生成式基座大模型的主流架构、典型预训练技术和适配微调等方法,介绍在大模型背景下模型剪枝、模型量化和知识蒸馏等大模型小型化关键技术的发展历史和研究近况,依据模型间协作目的及协同原理异同,提出大小模型协同训练、协同推理和协同规划的协同进化分类方法,概述端云模型双向蒸馏、模块化设计和生成式智能体等系列代表性新技术、新思路。总体而言,本文从生成式基座大模型、大模型小型化技术和大小模型端云协同方式3个方面探讨大小模型协同进化的国际和国内发展现状,对比优势和差距,并从应用前景、模型架构设计、垂直领域模型融合、个性化和安全可信挑战等层面分析基座赋能发展趋势。关键词:生成式大模型;大模型小型化;大小模型协同进化;端云协同进化;生成式智能体;生成式人工智能- 10
- |
- 6
- |
- 0
发布时间:2024-06-27 -
 摘要:随着数字媒体与创意产业的快速发展,人工智能生成内容(artificial intelligence generated content, AIGC)技术以其在视觉内容生成中的创新应用而逐渐受到关注。本文旨在围绕AIGC视觉内容生成与溯源研究进展深入研讨。首先,针对图像生成技术进行探讨,从基于生成式对抗网络的传统方法出发,系统地分析了基于生成式对抗网络、自回归模型和扩散概率模型的最新进展。接着,深入探讨可控图像生成技术,突出了通过布局、线稿等附加信息以及基于视觉参考的方法来为创作者提供精确控制的技术现状。随着图像生成技术的革新和应用,生成图像的安全性问题逐渐浮现。而预先审核和过滤的技术手段已难以满足实际需求,故亟需实现生成内容的溯源来进行监管。因此,本文进而对生成图像溯源技术进行研讨,并聚焦水印技术在确保生成内容可靠性和安全性方面的应用。依据水印嵌入的流程节点,首先将现有的水印相关的生成图像溯源方法归为无水印嵌入的生成图像溯源、水印前置嵌入的生成图像溯源、水印后置嵌入的生成图像溯源以及联合生成的生成图像溯源并进行详细分析,然后介绍针对生成图像的水印攻击研究现状,最后对生成图像溯源技术进行总结和展望。鉴于视觉内容生成在质量和安全上的挑战,旨在为研究者提供一个视觉内容生成与溯源的系统研究视角,以促进数字媒体创作环境的安全与可信,并引导未来相关技术的发展方向。关键词:人工智能内容生成 (AIGC);视觉内容生成;可控图像生成;生成内容安全;生成图像溯源
摘要:随着数字媒体与创意产业的快速发展,人工智能生成内容(artificial intelligence generated content, AIGC)技术以其在视觉内容生成中的创新应用而逐渐受到关注。本文旨在围绕AIGC视觉内容生成与溯源研究进展深入研讨。首先,针对图像生成技术进行探讨,从基于生成式对抗网络的传统方法出发,系统地分析了基于生成式对抗网络、自回归模型和扩散概率模型的最新进展。接着,深入探讨可控图像生成技术,突出了通过布局、线稿等附加信息以及基于视觉参考的方法来为创作者提供精确控制的技术现状。随着图像生成技术的革新和应用,生成图像的安全性问题逐渐浮现。而预先审核和过滤的技术手段已难以满足实际需求,故亟需实现生成内容的溯源来进行监管。因此,本文进而对生成图像溯源技术进行研讨,并聚焦水印技术在确保生成内容可靠性和安全性方面的应用。依据水印嵌入的流程节点,首先将现有的水印相关的生成图像溯源方法归为无水印嵌入的生成图像溯源、水印前置嵌入的生成图像溯源、水印后置嵌入的生成图像溯源以及联合生成的生成图像溯源并进行详细分析,然后介绍针对生成图像的水印攻击研究现状,最后对生成图像溯源技术进行总结和展望。鉴于视觉内容生成在质量和安全上的挑战,旨在为研究者提供一个视觉内容生成与溯源的系统研究视角,以促进数字媒体创作环境的安全与可信,并引导未来相关技术的发展方向。关键词:人工智能内容生成 (AIGC);视觉内容生成;可控图像生成;生成内容安全;生成图像溯源- 19
- |
- 6
- |
- 0
发布时间:2024-06-27 -
 摘要:大脑发育是神经系统结构和功能分化及成熟的一系列动态过程。大脑结构的发育包括部分脑区白质体积和完整性的增加,以及灰质体积的下降等;而这些结构的改变往往伴随着认知功能的变化,如智商、工作记忆和问题解决能力的提高以及社会认知的改善等。越来越多的发育研究为儿童青少年的教育干预提供了参考信息,帮助学校和家庭引导其从拥有冲动冒险心理状态的少年儿童阶段平稳过渡到心智更为成熟的成人阶段。脑图谱作为研究脑结构、脑功能及脑疾病的重要手段,是研究者对大脑进行解析的有力工具,在大脑发育研究中发挥着不可缺少的作用。本文立足于发育脑图谱,从3方面对儿童青少年大脑发育及脑图谱研究进展进行综述。首先,介绍儿童青少年发育阶段大脑特征的转变,以此来强调关注儿童青少年阶段大脑健康发育的重要性;其次,介绍现有的包括数据预处理步骤在内的发育图谱绘制的方法和手段;最后,对儿童和青少年图谱的研究进展进行描述,并分析当前研究对理解儿童青少年发育所做出的贡献以及它们的不足之处。对发育中的大脑进行研究,有利于增强对正常发育过程的了解,以针对性地对失衡的发育过程进行早期干预;通过对现有技术手段优缺点的总结,促进相关领域研究者开发更多以研究儿童青少年为导向的数据处理工具;综述具有精细划分的基于特定年龄儿童的大脑发育图谱,为未来的发育研究提供了强有力的研究工具的参考。这一综述有助于促进跨学科研究,推动儿童和青少年大脑发育领域的进展,从而为青少年的教育、健康和神经疾病研究提供更好的指导。关键词:儿童青少年;发育;大脑图谱;大脑模板;磁共振成像(MRI);发育数据集;预处理
摘要:大脑发育是神经系统结构和功能分化及成熟的一系列动态过程。大脑结构的发育包括部分脑区白质体积和完整性的增加,以及灰质体积的下降等;而这些结构的改变往往伴随着认知功能的变化,如智商、工作记忆和问题解决能力的提高以及社会认知的改善等。越来越多的发育研究为儿童青少年的教育干预提供了参考信息,帮助学校和家庭引导其从拥有冲动冒险心理状态的少年儿童阶段平稳过渡到心智更为成熟的成人阶段。脑图谱作为研究脑结构、脑功能及脑疾病的重要手段,是研究者对大脑进行解析的有力工具,在大脑发育研究中发挥着不可缺少的作用。本文立足于发育脑图谱,从3方面对儿童青少年大脑发育及脑图谱研究进展进行综述。首先,介绍儿童青少年发育阶段大脑特征的转变,以此来强调关注儿童青少年阶段大脑健康发育的重要性;其次,介绍现有的包括数据预处理步骤在内的发育图谱绘制的方法和手段;最后,对儿童和青少年图谱的研究进展进行描述,并分析当前研究对理解儿童青少年发育所做出的贡献以及它们的不足之处。对发育中的大脑进行研究,有利于增强对正常发育过程的了解,以针对性地对失衡的发育过程进行早期干预;通过对现有技术手段优缺点的总结,促进相关领域研究者开发更多以研究儿童青少年为导向的数据处理工具;综述具有精细划分的基于特定年龄儿童的大脑发育图谱,为未来的发育研究提供了强有力的研究工具的参考。这一综述有助于促进跨学科研究,推动儿童和青少年大脑发育领域的进展,从而为青少年的教育、健康和神经疾病研究提供更好的指导。关键词:儿童青少年;发育;大脑图谱;大脑模板;磁共振成像(MRI);发育数据集;预处理- 6
- |
- 0
- |
- 0
发布时间:2024-06-27 -
 摘要:人类智能是在与环境交互中进化的,因而如何实现智能体与环境的自主交互是推进智能演化的关键。环境自主交互是一项涉及计算机图形学、计算机视觉和机器人等多个学科领域的研究课题,引起广泛的关注和探究,学术界已围绕这一热点研究问题从不同视角和技术维度开展了一系列研究工作。本文着眼于室内场景拟人交互,全面梳理数字人与机器人在室内环境下学习完成特定交互任务过程中需要涉及的仿真交互平台、场景交互数据和交互生成算法3方面基本要素的研究进展。在仿真交互环境搭建方面,本文梳理了仿真环境涉及的仿真技术和研究进展,并对代表性的拟人交互仿真平台进行了介绍;在场景交互数据构建方面,本文从场景交互感知数据集、场景交互运动数据集以及交互数据规模的高效扩充3方面对国内外研究现状进行了详细介绍;在拟人交互感知与生成方面,本文介绍了以交互为导向的场景可供性分析的相关工作,并以交互生成为线索,分别梳理了数字人—场景交互生成、机器人—场景交互生成的相关工作。基于对国内外相关工作的梳理和讨论,最后从交互仿真、交互数据、交互感知和交互生成4个方面,总结了该领域目前仍面临的挑战,并对未来的发展趋势进行了展望。关键词:环境交互;交互仿真;交互数据;交互感知;交互生成
摘要:人类智能是在与环境交互中进化的,因而如何实现智能体与环境的自主交互是推进智能演化的关键。环境自主交互是一项涉及计算机图形学、计算机视觉和机器人等多个学科领域的研究课题,引起广泛的关注和探究,学术界已围绕这一热点研究问题从不同视角和技术维度开展了一系列研究工作。本文着眼于室内场景拟人交互,全面梳理数字人与机器人在室内环境下学习完成特定交互任务过程中需要涉及的仿真交互平台、场景交互数据和交互生成算法3方面基本要素的研究进展。在仿真交互环境搭建方面,本文梳理了仿真环境涉及的仿真技术和研究进展,并对代表性的拟人交互仿真平台进行了介绍;在场景交互数据构建方面,本文从场景交互感知数据集、场景交互运动数据集以及交互数据规模的高效扩充3方面对国内外研究现状进行了详细介绍;在拟人交互感知与生成方面,本文介绍了以交互为导向的场景可供性分析的相关工作,并以交互生成为线索,分别梳理了数字人—场景交互生成、机器人—场景交互生成的相关工作。基于对国内外相关工作的梳理和讨论,最后从交互仿真、交互数据、交互感知和交互生成4个方面,总结了该领域目前仍面临的挑战,并对未来的发展趋势进行了展望。关键词:环境交互;交互仿真;交互数据;交互感知;交互生成- 11
- |
- 1
- |
- 0
发布时间:2024-06-27 -
 摘要:情感计算是人工智能领域的一个重要分支,在交互、教育、安全和金融等众多领域应用广泛。单纯依靠语音、视频单一模态的情感识别并不符合人类对情感的感知模式,在受到干扰的情况下识别准确率会迅速下降。为了充分挖掘不同模态数据的互补性,多模态融合的情感识别研究正日益受到研究人员的广泛重视。本文分别从多模态情感识别概述、多模态情感识别与理解、抑郁症情感障碍检测及干预3个维度介绍多模态情感计算研究现状。本文认为具备可扩展性的情感特征设计、基于大模型迁移学习的识别方法将是未来的发展方向,并在解决抑郁、焦虑等情感障碍方面的作用日益凸显。关键词:情感识别;多模态融合;人机交互;抑郁状态评估;情感障碍干预;认知行为疗法
摘要:情感计算是人工智能领域的一个重要分支,在交互、教育、安全和金融等众多领域应用广泛。单纯依靠语音、视频单一模态的情感识别并不符合人类对情感的感知模式,在受到干扰的情况下识别准确率会迅速下降。为了充分挖掘不同模态数据的互补性,多模态融合的情感识别研究正日益受到研究人员的广泛重视。本文分别从多模态情感识别概述、多模态情感识别与理解、抑郁症情感障碍检测及干预3个维度介绍多模态情感计算研究现状。本文认为具备可扩展性的情感特征设计、基于大模型迁移学习的识别方法将是未来的发展方向,并在解决抑郁、焦虑等情感障碍方面的作用日益凸显。关键词:情感识别;多模态融合;人机交互;抑郁状态评估;情感障碍干预;认知行为疗法- 3
- |
- 0
- |
- 0
发布时间:2024-06-27
生成式大模型与人机交互
-
 摘要:医学超声作为一种无创、无辐射和实时医学成像模态,在重大疾病早期诊断和精准诊疗领域发挥重要作用。影像分辨率是超声仪器的核心指标,也是影响临床精准诊疗的关键。近年来,超声成像设备呈现多样化的发展趋势,以满足不同的临床应用场景,如超快速成像设备、便携成像设备等。然而,这些超声设备通常以牺牲成像质量来实现特定应用场景的要求,影响了其临床可用性。因此,为提升医学超声设备的诊断能力,研究如何获得高质量超声图像至关重要。本文回顾了近年来高质量超声图像成像的相关工作,从波束形成算法和高质量超声重建算法两方面进行介绍,波束形成算法方面,介绍了以延时叠加方法为代表的传统的非自适应方法,以及4类成像效果更优越但计算复杂度更高的自适应的波束形成方法,并对波束形成的深度学习类方法进行了简要介绍。对于高质量超声重建算法的讨论,则是从传统方法和深度学习方法两方面展开,并重点介绍了在高质量超声重建算法方面具有更广阔应用前景的深度学习技术,包括卷积神经网络方法、生成对抗网络方法等。最后,本文从研究方法的侧重点等方面比较国内外研究进展,并讨论了未来发展趋势。关键词:超声成像;波束形成;自适应成像;图像重建;高分辨率
摘要:医学超声作为一种无创、无辐射和实时医学成像模态,在重大疾病早期诊断和精准诊疗领域发挥重要作用。影像分辨率是超声仪器的核心指标,也是影响临床精准诊疗的关键。近年来,超声成像设备呈现多样化的发展趋势,以满足不同的临床应用场景,如超快速成像设备、便携成像设备等。然而,这些超声设备通常以牺牲成像质量来实现特定应用场景的要求,影响了其临床可用性。因此,为提升医学超声设备的诊断能力,研究如何获得高质量超声图像至关重要。本文回顾了近年来高质量超声图像成像的相关工作,从波束形成算法和高质量超声重建算法两方面进行介绍,波束形成算法方面,介绍了以延时叠加方法为代表的传统的非自适应方法,以及4类成像效果更优越但计算复杂度更高的自适应的波束形成方法,并对波束形成的深度学习类方法进行了简要介绍。对于高质量超声重建算法的讨论,则是从传统方法和深度学习方法两方面展开,并重点介绍了在高质量超声重建算法方面具有更广阔应用前景的深度学习技术,包括卷积神经网络方法、生成对抗网络方法等。最后,本文从研究方法的侧重点等方面比较国内外研究进展,并讨论了未来发展趋势。关键词:超声成像;波束形成;自适应成像;图像重建;高分辨率- 3
- |
- 0
- |
- 0
发布时间:2024-06-27 -
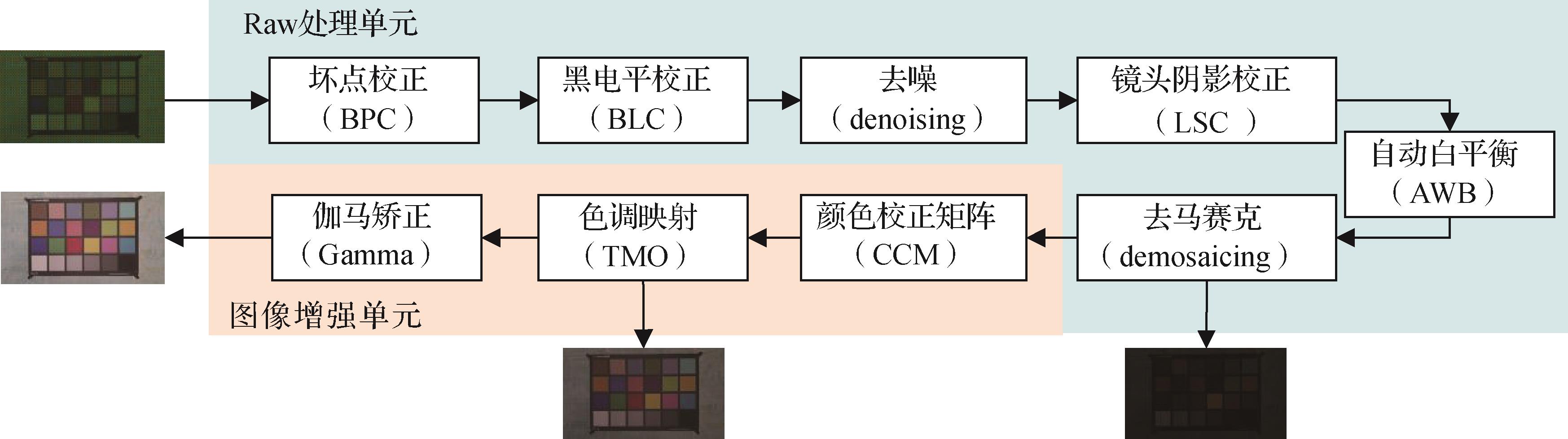 摘要:底层视觉重建技术旨在在受限的成像条件下重建高质量图像/视频,对后续视觉处理与呈现具有重要意义。由于像感域数据(raw data)具有高位宽、与感光量成线性响应等特点,近年来基于像感域的视觉重建技术在学术界和工业界获得的关注日益提高。本文聚焦于6种代表性视觉重建任务,包括低光增强与去噪、超分辨率、高动态范围重建、去摩尔纹、多任务联合重建以及数据生成,重点综述了深度学习驱动的像感域视觉重建领域的进展:系统地总结了领域代表性方法,概述各类方法的优势与局限,分析了不同任务中像感域数据相较于颜色域数据(经降噪、去马赛克、白平衡、色调映射和颜色空间转换(如RGB、sRGB等)等处理之后的数据)的独特属性与优势;梳理了各个领域的开源数据集,包括图像数据集、快速连拍数据集以及视频数据集,总结了数据集的构造方法以及配对数据的空间/时间对齐策略,为后续研究的数据集创建提供了参考与指引;总结了现有方法存在的问题与困境,展望了像感域底层视觉重建的发展趋势。关键词:像感域(Raw域)图像重建;Raw域图像(视频)低光增强;Raw域图像(视频)去噪;Raw域图像(视频)超分辨率;Raw域图像(视频)高动态范围重建;Raw域图像(视频)去摩尔纹
摘要:底层视觉重建技术旨在在受限的成像条件下重建高质量图像/视频,对后续视觉处理与呈现具有重要意义。由于像感域数据(raw data)具有高位宽、与感光量成线性响应等特点,近年来基于像感域的视觉重建技术在学术界和工业界获得的关注日益提高。本文聚焦于6种代表性视觉重建任务,包括低光增强与去噪、超分辨率、高动态范围重建、去摩尔纹、多任务联合重建以及数据生成,重点综述了深度学习驱动的像感域视觉重建领域的进展:系统地总结了领域代表性方法,概述各类方法的优势与局限,分析了不同任务中像感域数据相较于颜色域数据(经降噪、去马赛克、白平衡、色调映射和颜色空间转换(如RGB、sRGB等)等处理之后的数据)的独特属性与优势;梳理了各个领域的开源数据集,包括图像数据集、快速连拍数据集以及视频数据集,总结了数据集的构造方法以及配对数据的空间/时间对齐策略,为后续研究的数据集创建提供了参考与指引;总结了现有方法存在的问题与困境,展望了像感域底层视觉重建的发展趋势。关键词:像感域(Raw域)图像重建;Raw域图像(视频)低光增强;Raw域图像(视频)去噪;Raw域图像(视频)超分辨率;Raw域图像(视频)高动态范围重建;Raw域图像(视频)去摩尔纹- 4
- |
- 1
- |
- 0
发布时间:2024-06-27 -
 摘要:恶劣场景下采集的图像与视频数据存在复杂的视觉降质,一方面降低视觉呈现与感知体验,另一方面也为视觉分析理解带来了很大困难。为此,系统地分析了国际国内近年恶劣场景下视觉感知与理解领域的重要研究进展,包括图像视频与降质建模、恶劣场景视觉增强、恶劣场景下视觉分析理解等技术。其中,视觉数据与降质建模部分探讨了不同降质场景下的图像视频与降质过程建模方法,涵盖噪声建模、降采样建模、光照建模和雨雾建模。传统恶劣场景视觉增强部分探讨了早期非深度学习的视觉增强算法,包括直方图均衡化、视网膜大脑皮层理论和滤波方法等。基于深度学习模型的恶劣场景视觉增强部分则以模型架构创新的角度进行梳理,探讨了卷积神经网络、Transformer模型和扩散模型等架构。不同于传统视觉增强的目标为全面提升人眼对图像视频的视觉感知效果,新一代视觉增强及分析方法考虑降质场景下机器视觉对图像视频的理解性能。恶劣场景下视觉理解技术部分探讨了恶劣场景下视觉理解数据集和基于深度学习模型的恶劣场景视觉理解,以及恶劣场景下视觉增强与理解协同计算。论文详细综述了上述研究的挑战性,梳理了国内外技术发展脉络和前沿动态。最后,根据上述分析展望了恶劣场景下视觉感知与理解的发展方向。关键词:恶劣场景;视觉感知;视觉理解;图像视频增强;图像视频处理;深度学习
摘要:恶劣场景下采集的图像与视频数据存在复杂的视觉降质,一方面降低视觉呈现与感知体验,另一方面也为视觉分析理解带来了很大困难。为此,系统地分析了国际国内近年恶劣场景下视觉感知与理解领域的重要研究进展,包括图像视频与降质建模、恶劣场景视觉增强、恶劣场景下视觉分析理解等技术。其中,视觉数据与降质建模部分探讨了不同降质场景下的图像视频与降质过程建模方法,涵盖噪声建模、降采样建模、光照建模和雨雾建模。传统恶劣场景视觉增强部分探讨了早期非深度学习的视觉增强算法,包括直方图均衡化、视网膜大脑皮层理论和滤波方法等。基于深度学习模型的恶劣场景视觉增强部分则以模型架构创新的角度进行梳理,探讨了卷积神经网络、Transformer模型和扩散模型等架构。不同于传统视觉增强的目标为全面提升人眼对图像视频的视觉感知效果,新一代视觉增强及分析方法考虑降质场景下机器视觉对图像视频的理解性能。恶劣场景下视觉理解技术部分探讨了恶劣场景下视觉理解数据集和基于深度学习模型的恶劣场景视觉理解,以及恶劣场景下视觉增强与理解协同计算。论文详细综述了上述研究的挑战性,梳理了国内外技术发展脉络和前沿动态。最后,根据上述分析展望了恶劣场景下视觉感知与理解的发展方向。关键词:恶劣场景;视觉感知;视觉理解;图像视频增强;图像视频处理;深度学习- 5
- |
- 3
- |
- 0
发布时间:2024-06-27
图像重建与视频增强
-
 摘要:对于少数民族古籍的保护与传承,国家予以高度重视,并强调了对这些不可再生文化资源透彻数字化的重要性。随着文档图像分析与识别技术的不断进步,对少数民族文字的文本分析与识别研究受到广泛关注,并取得显著成就,成为人工智能应用研究的一个热点领域。然而,由于少数民族文字种类繁多、应用场景多样及数据集的稀缺性等问题,这一研究领域仍面临诸多挑战。本文旨在总结先前的工作,并为未来的研究提供支持,重点讨论了印刷体文本、联机手写、古籍文档及场景文字识别等任务,概述了国内外在少数民族文种识别领域的发展和最新成果。首先阐明了少数民族文字文本分析与识别的重要性及其价值,介绍了特定少数民族文字及其古籍文档的特征。然后,回顾了这一领域的发展历史和现状,分析并总结了传统方法的代表性成果及其应用;详细讨论了研究重点向深度神经网络模型和深度学习方法的全面转移,这一转变使得各文种的识别性能得到了显著提升。最后,基于相关分析,本文指出了在不同文种文档分析与识别中存在的精度和泛化能力等方面的不足,以及与汉文文本分析与识别的差异;面对少数民族文字文本识别领域的主要困难与挑战,展望了未来的研究趋势和技术发展目标。关键词:少数民族文字;文档分析与识别;印刷体文本识别;手写识别;古籍文档识别;场景文字识别
摘要:对于少数民族古籍的保护与传承,国家予以高度重视,并强调了对这些不可再生文化资源透彻数字化的重要性。随着文档图像分析与识别技术的不断进步,对少数民族文字的文本分析与识别研究受到广泛关注,并取得显著成就,成为人工智能应用研究的一个热点领域。然而,由于少数民族文字种类繁多、应用场景多样及数据集的稀缺性等问题,这一研究领域仍面临诸多挑战。本文旨在总结先前的工作,并为未来的研究提供支持,重点讨论了印刷体文本、联机手写、古籍文档及场景文字识别等任务,概述了国内外在少数民族文种识别领域的发展和最新成果。首先阐明了少数民族文字文本分析与识别的重要性及其价值,介绍了特定少数民族文字及其古籍文档的特征。然后,回顾了这一领域的发展历史和现状,分析并总结了传统方法的代表性成果及其应用;详细讨论了研究重点向深度神经网络模型和深度学习方法的全面转移,这一转变使得各文种的识别性能得到了显著提升。最后,基于相关分析,本文指出了在不同文种文档分析与识别中存在的精度和泛化能力等方面的不足,以及与汉文文本分析与识别的差异;面对少数民族文字文本识别领域的主要困难与挑战,展望了未来的研究趋势和技术发展目标。关键词:少数民族文字;文档分析与识别;印刷体文本识别;手写识别;古籍文档识别;场景文字识别- 3
- |
- 0
- |
- 0
发布时间:2024-06-27 -
 摘要:相对于自然图像和多光谱图像,高光谱图像包含丰富的空间—光谱信息,不仅能够保留目标的空间信息,还能够获取高度可辨别的光谱信息。因此,如变化检测、目标追踪等高光谱图像处理技术在对地观测任务中得到了广泛应用。然而,在高光谱图像变化检测的过程中仍然存在许多问题与挑战。如高光谱图像的高维复杂性、光谱差异性以及存在光谱混合等问题,影响变化检测效果。得益于深度学习理论的深入研究,高光谱图像变化检测技术研究得到了极大的发展。本文对现有基于深度学习的变化检测方法进行全面分析总结,按照高光谱图像采集条件是否相同,将其分为同构高光谱图像变化检测以及异构高光谱图像变化检测。其中,从特征提取的网络结构优化和特征提取前混合像素处理两个角度,又将同构高光谱图像变化检测方法进一步分为基于时序依赖和空谱信息提取的方法以及基于端元提取和解混的方法,分别总结各类方法的特点和局限性,并讨论未来的研究重点。此外,面对不同传感器获取的异构高光谱图像数据,现有的方法基于图论学习图像的结构关系,并基于图像变换将其转换至公共域从而进行变化检测处理。本文从高光谱图像变化检测领域的新设计、新方法和应用场景出发,通过综合国内外前沿文献来梳理该领域的主要发展,重点论述高光谱图像变化检测领域的发展现状、前沿动态、热点问题及趋势。关键词:高光谱图像;变化检测;时序特征提取;端元解混;异构高光谱图像变化检测
摘要:相对于自然图像和多光谱图像,高光谱图像包含丰富的空间—光谱信息,不仅能够保留目标的空间信息,还能够获取高度可辨别的光谱信息。因此,如变化检测、目标追踪等高光谱图像处理技术在对地观测任务中得到了广泛应用。然而,在高光谱图像变化检测的过程中仍然存在许多问题与挑战。如高光谱图像的高维复杂性、光谱差异性以及存在光谱混合等问题,影响变化检测效果。得益于深度学习理论的深入研究,高光谱图像变化检测技术研究得到了极大的发展。本文对现有基于深度学习的变化检测方法进行全面分析总结,按照高光谱图像采集条件是否相同,将其分为同构高光谱图像变化检测以及异构高光谱图像变化检测。其中,从特征提取的网络结构优化和特征提取前混合像素处理两个角度,又将同构高光谱图像变化检测方法进一步分为基于时序依赖和空谱信息提取的方法以及基于端元提取和解混的方法,分别总结各类方法的特点和局限性,并讨论未来的研究重点。此外,面对不同传感器获取的异构高光谱图像数据,现有的方法基于图论学习图像的结构关系,并基于图像变换将其转换至公共域从而进行变化检测处理。本文从高光谱图像变化检测领域的新设计、新方法和应用场景出发,通过综合国内外前沿文献来梳理该领域的主要发展,重点论述高光谱图像变化检测领域的发展现状、前沿动态、热点问题及趋势。关键词:高光谱图像;变化检测;时序特征提取;端元解混;异构高光谱图像变化检测- 4
- |
- 0
- |
- 0
发布时间:2024-06-27 -
 摘要:遥感对地观测中普遍存在多平台、多传感器和多角度的多源数据,为遥感场景解译提供协同互补信息。然而,现有的场景解译方法需要根据不同遥感场景数据训练模型,或者对测试数据标准化以适应现有模型,训练成本高、响应周期长,已无法适应多源数据协同解译的新阶段。跨域遥感场景解译将已训练的老模型迁移到新的应用场景,通过模型复用以适应不同场景变化,利用已有领域的知识来解决未知领域问题。本文以跨域遥感场景解译为主线,综合分析国内外文献,结合场景识别和目标识别两个典型任务,论述国内外研究现状、前沿热点和未来趋势,梳理总结跨域遥感场景解译的常用数据集和统一的实验设置。本文实验数据集及检测结果的公开链接为:https://github.com/XiangtaoZheng/CDRSSI。关键词:跨域遥感场景解译;分布外泛化;模型泛化;多样性数据集;迁移学习;自适应算法
摘要:遥感对地观测中普遍存在多平台、多传感器和多角度的多源数据,为遥感场景解译提供协同互补信息。然而,现有的场景解译方法需要根据不同遥感场景数据训练模型,或者对测试数据标准化以适应现有模型,训练成本高、响应周期长,已无法适应多源数据协同解译的新阶段。跨域遥感场景解译将已训练的老模型迁移到新的应用场景,通过模型复用以适应不同场景变化,利用已有领域的知识来解决未知领域问题。本文以跨域遥感场景解译为主线,综合分析国内外文献,结合场景识别和目标识别两个典型任务,论述国内外研究现状、前沿热点和未来趋势,梳理总结跨域遥感场景解译的常用数据集和统一的实验设置。本文实验数据集及检测结果的公开链接为:https://github.com/XiangtaoZheng/CDRSSI。关键词:跨域遥感场景解译;分布外泛化;模型泛化;多样性数据集;迁移学习;自适应算法- 6
- |
- 2
- |
- 0
发布时间:2024-06-27 -
 摘要:三维视觉推理的核心思想是对点云场景中的视觉主体间的关系进行理解。非专业用户难以向计算机传达自己的意图,从而限制了该技术的普及与推广。为此,研究人员以自然语言作为语义背景和查询条件反映用户意图,进而与点云的信息进行交互以完成相应的任务。此种范式称做“三维视觉—语言”推理,在自动驾驶、机器人导航以及人机交互等众多领域广泛应用,已经成为计算机视觉领域中备受瞩目的研究方向。过去几年间,“三维视觉—语言”推理技术迅猛发展,呈现出百花齐放的趋势,但是目前依然缺乏对最新研究进展的全面总结。本文聚焦于两类最具代表性的研究工作,锚框预测和内容生成类的“三维视觉—语言”推理技术,系统性概括领域内研究的最新进展。首先,本文总结了“三维视觉—语言”推理的问题定义和现存挑战,同时概述了一些常见的骨干网络。其次,本文按照方法所关注的下游场景,对两类“三维视觉—语言”推理技术做了进一步细分,并深入探讨了各方法的优缺点。接下来,本文对比分析了各类方法在不同基准数据集上的性能。最后,本文展望了“三维视觉—语言”推理技术的未来发展前景,以期促进该领域的深入研究与广泛应用。关键词:深度学习;计算机视觉;“三维视觉—语言”推理;跨模态学习;视觉定位;密集字幕生成;视觉问答;场景生成
摘要:三维视觉推理的核心思想是对点云场景中的视觉主体间的关系进行理解。非专业用户难以向计算机传达自己的意图,从而限制了该技术的普及与推广。为此,研究人员以自然语言作为语义背景和查询条件反映用户意图,进而与点云的信息进行交互以完成相应的任务。此种范式称做“三维视觉—语言”推理,在自动驾驶、机器人导航以及人机交互等众多领域广泛应用,已经成为计算机视觉领域中备受瞩目的研究方向。过去几年间,“三维视觉—语言”推理技术迅猛发展,呈现出百花齐放的趋势,但是目前依然缺乏对最新研究进展的全面总结。本文聚焦于两类最具代表性的研究工作,锚框预测和内容生成类的“三维视觉—语言”推理技术,系统性概括领域内研究的最新进展。首先,本文总结了“三维视觉—语言”推理的问题定义和现存挑战,同时概述了一些常见的骨干网络。其次,本文按照方法所关注的下游场景,对两类“三维视觉—语言”推理技术做了进一步细分,并深入探讨了各方法的优缺点。接下来,本文对比分析了各类方法在不同基准数据集上的性能。最后,本文展望了“三维视觉—语言”推理技术的未来发展前景,以期促进该领域的深入研究与广泛应用。关键词:深度学习;计算机视觉;“三维视觉—语言”推理;跨模态学习;视觉定位;密集字幕生成;视觉问答;场景生成- 5
- |
- 2
- |
- 0
发布时间:2024-06-27 -
 摘要:在数字仿真技术应用领域,特别是在自动驾驶技术的发展中,目标检测是至关重要的一个环节,它涉及对周围环境中物体的感知,为智能装备的决策和规划提供了关键信息。近年来,随着传感器技术的进步,图像和点云成为两种主要的感知数据源,它们各自在基于深度学习技术的目标检测方法研究中具有独特的优势。为了更加全面地对现有基于点云和图像的目标检测方法进行研究,本文对基于图像、点云及两者联合的3类目标检测算法进行系统的梳理和总结,旨在探索如何将这两种数据源融合起来,促进提高目标检测的准确性、稳定性和鲁棒性,并对融合点云和图像的环境目标检测发展方向进行展望。关键词:点云;自动驾驶;多模态;目标检测;融合
摘要:在数字仿真技术应用领域,特别是在自动驾驶技术的发展中,目标检测是至关重要的一个环节,它涉及对周围环境中物体的感知,为智能装备的决策和规划提供了关键信息。近年来,随着传感器技术的进步,图像和点云成为两种主要的感知数据源,它们各自在基于深度学习技术的目标检测方法研究中具有独特的优势。为了更加全面地对现有基于点云和图像的目标检测方法进行研究,本文对基于图像、点云及两者联合的3类目标检测算法进行系统的梳理和总结,旨在探索如何将这两种数据源融合起来,促进提高目标检测的准确性、稳定性和鲁棒性,并对融合点云和图像的环境目标检测发展方向进行展望。关键词:点云;自动驾驶;多模态;目标检测;融合- 4
- |
- 2
- |
- 0
发布时间:2024-06-27
场景识别与跨模态学习
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0