
最新刊期
2024 年 第 29 卷 第 10 期

-
 摘要:单目视觉惯性同步定位与地图构建(visual-inertial simultaneous localization and mapping,VI-SLAM)技术因具有硬件成本低、无需对外部环境进行布置等优点,得到了广泛关注,在过去的十多年里取得了长足的进步,涌现出诸多优秀的方法和系统。由于实际场景的复杂性,不同方法难免有各自的局限性。虽然已经有一些工作对VI-SLAM方法进行了综述和评测,但大多只针对经典的VI-SLAM方法,已不能充分反映最新的VI-SLAM技术发展现状。本文首先对基于单目VI-SLAM方法的基本原理进行阐述,然后对单目VI-SLAM方法进行分类分析。为了综合全面地对比不同方法之间的优劣势,本文特别选取3个公开数据集对代表性的单目VI-SLAM方法从多个维度上进行定量评测,全面系统地分析了各类方法在实际场景尤其是增强现实应用场景中的性能。实验结果表明,基于优化或滤波和优化相结合的方法一般在跟踪精度和鲁棒性上比基于滤波的方法有优势,直接法/半直接法在全局快门拍摄的情况下精度较高,但容易受卷帘快门和光照变化的影响,尤其是大场景下误差累积较快;结合深度学习可以提高极端情况下的鲁棒性。最后,针对深度学习与V-SLAM/VI-SLAM结合、多传感器融合以及端云协同这3个研究热点,对SLAM的发展趋势进行讨论和展望。关键词:视觉惯性同步定位与地图构建(VI-SLAM);增强现实(AR);视觉惯性数据集;多视图几何;多传感器融合886|1690|0更新时间:2024-10-23
摘要:单目视觉惯性同步定位与地图构建(visual-inertial simultaneous localization and mapping,VI-SLAM)技术因具有硬件成本低、无需对外部环境进行布置等优点,得到了广泛关注,在过去的十多年里取得了长足的进步,涌现出诸多优秀的方法和系统。由于实际场景的复杂性,不同方法难免有各自的局限性。虽然已经有一些工作对VI-SLAM方法进行了综述和评测,但大多只针对经典的VI-SLAM方法,已不能充分反映最新的VI-SLAM技术发展现状。本文首先对基于单目VI-SLAM方法的基本原理进行阐述,然后对单目VI-SLAM方法进行分类分析。为了综合全面地对比不同方法之间的优劣势,本文特别选取3个公开数据集对代表性的单目VI-SLAM方法从多个维度上进行定量评测,全面系统地分析了各类方法在实际场景尤其是增强现实应用场景中的性能。实验结果表明,基于优化或滤波和优化相结合的方法一般在跟踪精度和鲁棒性上比基于滤波的方法有优势,直接法/半直接法在全局快门拍摄的情况下精度较高,但容易受卷帘快门和光照变化的影响,尤其是大场景下误差累积较快;结合深度学习可以提高极端情况下的鲁棒性。最后,针对深度学习与V-SLAM/VI-SLAM结合、多传感器融合以及端云协同这3个研究热点,对SLAM的发展趋势进行讨论和展望。关键词:视觉惯性同步定位与地图构建(VI-SLAM);增强现实(AR);视觉惯性数据集;多视图几何;多传感器融合886|1690|0更新时间:2024-10-23 -
 摘要:随着软件技术的快速发展以及硬件设备的不断更新,增强现实技术已逐步成熟并广泛应用于各个领域。在增强现实中,虚实遮挡处理是实现虚拟世界和真实世界无缝融合的前提,对提升用户的沉浸感和真实感具有重要的研究意义。该技术通过建立尽可能精确的虚实物体遮挡关系以呈现逼真的虚实融合效果,使得用户能够正确地感知虚拟物体和真实物体的空间位置关系,从而提升交互体验。本文首先介绍了虚实遮挡的相关背景、概念和总体处理流程。然后针对刚性物体和非刚性物体的不同特点,总结了现有的基于深度、基于图像分析和基于模型3类虚实遮挡处理方法的具体原理、代表性研究工作以及它们对刚性物体和非刚性物体的适用性。在此基础上,从实时性、自动化程度、是否支持动态场景及适用范围等多个角度对现有的虚实遮挡方法进行了对比分析,并归纳了3类虚实遮挡处理方法的具体流程、难点以及局限性。最后针对相关工作中存在的问题,提出了目前虚实遮挡技术所面临的挑战以及未来可能的研究方向,希望能为后续的研究工作提供参考。关键词:增强现实;虚实遮挡;刚体及非刚体;深度图修复;前景提取602|875|0更新时间:2024-10-23
摘要:随着软件技术的快速发展以及硬件设备的不断更新,增强现实技术已逐步成熟并广泛应用于各个领域。在增强现实中,虚实遮挡处理是实现虚拟世界和真实世界无缝融合的前提,对提升用户的沉浸感和真实感具有重要的研究意义。该技术通过建立尽可能精确的虚实物体遮挡关系以呈现逼真的虚实融合效果,使得用户能够正确地感知虚拟物体和真实物体的空间位置关系,从而提升交互体验。本文首先介绍了虚实遮挡的相关背景、概念和总体处理流程。然后针对刚性物体和非刚性物体的不同特点,总结了现有的基于深度、基于图像分析和基于模型3类虚实遮挡处理方法的具体原理、代表性研究工作以及它们对刚性物体和非刚性物体的适用性。在此基础上,从实时性、自动化程度、是否支持动态场景及适用范围等多个角度对现有的虚实遮挡方法进行了对比分析,并归纳了3类虚实遮挡处理方法的具体流程、难点以及局限性。最后针对相关工作中存在的问题,提出了目前虚实遮挡技术所面临的挑战以及未来可能的研究方向,希望能为后续的研究工作提供参考。关键词:增强现实;虚实遮挡;刚体及非刚体;深度图修复;前景提取602|875|0更新时间:2024-10-23 -
 摘要:视觉定位旨在从已知的三维场景中恢复当前观测图像的相机位姿。视觉定位技术具备低成本、高精度和易于集成等优势,是实现计算设备与真实世界建立智能交互过程的关键技术之一,如今获得了混合现实、自动驾驶等应用领域的广泛关注。作为计算机视觉领域长期探索的基础任务之一,视觉定位方法至今已取得显著的研究进展,然而现有方法普遍存在计算开销和存储占用过大等不足,这些问题导致视觉定位在移动端的高效部署和场景模型的更新维护方面存在困难,并因此在很大程度上限制着视觉定位技术的实际应用。针对这一问题,部分研究工作开始聚焦于推动视觉定位技术的轻量化发展。轻量化视觉定位旨在研究更加高效的场景表达形式及其视觉定位方法,目前正逐渐成为视觉定位领域重要的研究方向。本文首先回顾早期视觉定位框架,随后从场景表达形式的角度对具备轻量化特性的现有视觉定位研究工作进行分类。在各个方法类别下,分析总结其特点优势、应用场景和技术难点,并同时介绍代表性成果。进一步地,本文对部分轻量化视觉定位的代表性方法在常用室内外数据集上的性能表现进行对比分析,评估指标主要包含离线建图的用时、场景地图的存储占用和定位精度3个维度。现有的轻量化视觉定位技术仍然面临着诸多的难题与挑战,场景模型的表达能力、定位方法的泛化性与鲁棒性尚存在较大的提升空间。最后,本文对轻量化视觉定位未来的发展趋势进行分析与展望。关键词:视觉定位;相机位姿估计;三维场景表达;轻量化地图;特征匹配;场景坐标回归;位姿回归715|1117|0更新时间:2024-10-23
摘要:视觉定位旨在从已知的三维场景中恢复当前观测图像的相机位姿。视觉定位技术具备低成本、高精度和易于集成等优势,是实现计算设备与真实世界建立智能交互过程的关键技术之一,如今获得了混合现实、自动驾驶等应用领域的广泛关注。作为计算机视觉领域长期探索的基础任务之一,视觉定位方法至今已取得显著的研究进展,然而现有方法普遍存在计算开销和存储占用过大等不足,这些问题导致视觉定位在移动端的高效部署和场景模型的更新维护方面存在困难,并因此在很大程度上限制着视觉定位技术的实际应用。针对这一问题,部分研究工作开始聚焦于推动视觉定位技术的轻量化发展。轻量化视觉定位旨在研究更加高效的场景表达形式及其视觉定位方法,目前正逐渐成为视觉定位领域重要的研究方向。本文首先回顾早期视觉定位框架,随后从场景表达形式的角度对具备轻量化特性的现有视觉定位研究工作进行分类。在各个方法类别下,分析总结其特点优势、应用场景和技术难点,并同时介绍代表性成果。进一步地,本文对部分轻量化视觉定位的代表性方法在常用室内外数据集上的性能表现进行对比分析,评估指标主要包含离线建图的用时、场景地图的存储占用和定位精度3个维度。现有的轻量化视觉定位技术仍然面临着诸多的难题与挑战,场景模型的表达能力、定位方法的泛化性与鲁棒性尚存在较大的提升空间。最后,本文对轻量化视觉定位未来的发展趋势进行分析与展望。关键词:视觉定位;相机位姿估计;三维场景表达;轻量化地图;特征匹配;场景坐标回归;位姿回归715|1117|0更新时间:2024-10-23 -
 摘要:可微渲染技术是当前计算机图形学与计算机视觉方向的研究热点,其目标是将计算机图形学中的渲染流水线进行可微化改造以支持计算渲染的输出图像关于输入参数如几何、材质等参数的梯度。结合渲染图像与目标图像之间的损失函数,可微渲染允许在生成式分析的框架中,通过梯度下降的方式从图像中推理出场景参数,是解决三维重建、逆向渲染等领域问题的有效方法,并在虚拟现实、自动驾驶等领域有着广泛的应用前景。基于物理的可微渲染旨在对基于物理的渲染管线进行可微化改造,主要涉及对场景几何和材质的表达,以及光路传输模拟过程的梯度计算方法。本文对近年来基于物理的可微渲染领域的发展情况进行了调研,总结了基于物理的可微渲染研究进展。首先总体介绍正向渲染和可微渲染的计算方法;然后介绍如何针对具体的几何、材质以及相机的表达方式进行梯度计算;讨论如何提高可微渲染的效率和鲁棒性;展示可微渲染如何应用于实际任务中;最后本文展望了可微渲染的发展趋势,期望推动该领域的进一步发展。关键词:渲染;可微渲染;逆向渲染;光线跟踪;三维重建882|1288|0更新时间:2024-10-23
摘要:可微渲染技术是当前计算机图形学与计算机视觉方向的研究热点,其目标是将计算机图形学中的渲染流水线进行可微化改造以支持计算渲染的输出图像关于输入参数如几何、材质等参数的梯度。结合渲染图像与目标图像之间的损失函数,可微渲染允许在生成式分析的框架中,通过梯度下降的方式从图像中推理出场景参数,是解决三维重建、逆向渲染等领域问题的有效方法,并在虚拟现实、自动驾驶等领域有着广泛的应用前景。基于物理的可微渲染旨在对基于物理的渲染管线进行可微化改造,主要涉及对场景几何和材质的表达,以及光路传输模拟过程的梯度计算方法。本文对近年来基于物理的可微渲染领域的发展情况进行了调研,总结了基于物理的可微渲染研究进展。首先总体介绍正向渲染和可微渲染的计算方法;然后介绍如何针对具体的几何、材质以及相机的表达方式进行梯度计算;讨论如何提高可微渲染的效率和鲁棒性;展示可微渲染如何应用于实际任务中;最后本文展望了可微渲染的发展趋势,期望推动该领域的进一步发展。关键词:渲染;可微渲染;逆向渲染;光线跟踪;三维重建882|1288|0更新时间:2024-10-23 -
 摘要:随着虚拟现实、元宇宙以及生成式人工智能等自然人机交互技术的发展,以交互式虚拟内容为主的人机界面正在给用户提供一种新型的任务挑战——情感挑战。情感挑战主要考察人对虚拟世界情感的理解、探索和处理能力,是元宇宙虚拟交互场景承载的核心内容,也是未来数字世界不可或缺的重要元素。情感挑战自2015年提出以来,一直受到人机交互领域高度关注。在此背景下,国内外研究者们围绕情感挑战的定义和特性、交互设计、评估量表和计算建模等方面开展了一系列研究工作,本文主要对这些工作进行系统化整理和介绍,并对情感挑战在元宇宙中的应用前景进行展望。首先,本文从传统数字游戏中的物理挑战和认知挑战出发,介绍情感挑战的发现、提出、完善和应用;其次,本文对虚拟现实中的情感挑战交互效应研究和情感挑战计算建模方法进行了介绍;然后,本文基于已有工作,从人机交互的角度给出了情感挑战的定义,介绍了情感挑战存在的主要媒介和设计方法;最后,本文总结了情感挑战在元宇宙中的研究意义,并对情感挑战在元宇宙中的应用前景进行了展望。关键词:情感挑战;叙事性游戏;虚拟现实(VR);元宇宙;人机交互356|620|0更新时间:2024-10-23
摘要:随着虚拟现实、元宇宙以及生成式人工智能等自然人机交互技术的发展,以交互式虚拟内容为主的人机界面正在给用户提供一种新型的任务挑战——情感挑战。情感挑战主要考察人对虚拟世界情感的理解、探索和处理能力,是元宇宙虚拟交互场景承载的核心内容,也是未来数字世界不可或缺的重要元素。情感挑战自2015年提出以来,一直受到人机交互领域高度关注。在此背景下,国内外研究者们围绕情感挑战的定义和特性、交互设计、评估量表和计算建模等方面开展了一系列研究工作,本文主要对这些工作进行系统化整理和介绍,并对情感挑战在元宇宙中的应用前景进行展望。首先,本文从传统数字游戏中的物理挑战和认知挑战出发,介绍情感挑战的发现、提出、完善和应用;其次,本文对虚拟现实中的情感挑战交互效应研究和情感挑战计算建模方法进行了介绍;然后,本文基于已有工作,从人机交互的角度给出了情感挑战的定义,介绍了情感挑战存在的主要媒介和设计方法;最后,本文总结了情感挑战在元宇宙中的研究意义,并对情感挑战在元宇宙中的应用前景进行了展望。关键词:情感挑战;叙事性游戏;虚拟现实(VR);元宇宙;人机交互356|620|0更新时间:2024-10-23 -
 摘要:随着信息技术的发展,混合现实(mixed reality, MR)技术已应用于医疗、教育和辅助引导等众多领域。MR场景包含丰富的语义信息,基于场景上下文信息的混合现实技术可以改善用户对场景的感知,优化用户的交互操作、提升交互模型的准确度,受到广泛关注。然而,目前在该领域没有针对上下文信息进行调查的综述类文献,缺乏梳理与分类。本文的研究对象是使用上下文信息的MR技术与系统。通过对MR领域的文献调研,本文提出了3个研究问题,并对国外近20年的33篇实证研究论文进行分析,概述了使用上下文信息的MR技术的最新发展,从3个维度出发进行分类学研究并分别提出分类标准,如上下文信息种类、上下文知识库的构建方式和应用领域等。其中,上下文信息的种类可以分为场景语义、对象语义、空间关系、群组关系、从属关系和运动信息6类,知识库的构建按用户介入角度和基础技术类型划分,应用领域从场景类型和生成式特性出发进行分类。通过对不同维度对研究对象的分类,本文对提出的研究问题进行了回应,并总结了现阶段的不足以及未来可能的研究方向。本综述可以辅助不同领域的研究人员对上下文信息的设计、选择和评估,从而推动未来混合现实应用技术与系统的研发。关键词:虚拟现实(VR);增强现实(AR);感知与交互;上下文信息;场景语义385|603|0更新时间:2024-10-23
摘要:随着信息技术的发展,混合现实(mixed reality, MR)技术已应用于医疗、教育和辅助引导等众多领域。MR场景包含丰富的语义信息,基于场景上下文信息的混合现实技术可以改善用户对场景的感知,优化用户的交互操作、提升交互模型的准确度,受到广泛关注。然而,目前在该领域没有针对上下文信息进行调查的综述类文献,缺乏梳理与分类。本文的研究对象是使用上下文信息的MR技术与系统。通过对MR领域的文献调研,本文提出了3个研究问题,并对国外近20年的33篇实证研究论文进行分析,概述了使用上下文信息的MR技术的最新发展,从3个维度出发进行分类学研究并分别提出分类标准,如上下文信息种类、上下文知识库的构建方式和应用领域等。其中,上下文信息的种类可以分为场景语义、对象语义、空间关系、群组关系、从属关系和运动信息6类,知识库的构建按用户介入角度和基础技术类型划分,应用领域从场景类型和生成式特性出发进行分类。通过对不同维度对研究对象的分类,本文对提出的研究问题进行了回应,并总结了现阶段的不足以及未来可能的研究方向。本综述可以辅助不同领域的研究人员对上下文信息的设计、选择和评估,从而推动未来混合现实应用技术与系统的研发。关键词:虚拟现实(VR);增强现实(AR);感知与交互;上下文信息;场景语义385|603|0更新时间:2024-10-23 -
 摘要:在大型高分辨显示器和头戴式显式设备中实现实时、逼真的渲染仍然是计算机图形学面临的主要挑战之一。注视点渲染(foveated rendering)利用人类视觉系统的局限性,根据注视点调整图像渲染质量,从而在不损失用户感知质量的前提下大大提高渲染速度。随着深度学习方法在渲染领域的广泛应用,涌现出大量基于深度学习的注视点渲染新方法。本文从深度学习的角度对注视点渲染领域的最新方法进行综述。首先,概述了人类视觉感知的背景知识。接着,简要介绍了注视点渲染中最具代表性的非深度学习方法,包括自适应分辨率、几何简化、着色简化和硬件实现,并总结了这些方法的优缺点。随后,描述了文中用于评估深度学习不同方法所使用的评估准则,包括常用的注视点渲染图像的评估指标和注视点预测评估指标。接下来,将注视点渲染中的深度学习方法细分为超分辨率、降噪、补全、图像合成、注视点预测和图像应用,对它们进行详细概述和总结。最后,提出了深度学习方法目前面临的问题和挑战。通过对注视点渲染领域的深度学习方法的讨论,可以更详细地展示深度学习在注视点渲染中的研究前景和发展方向,对后续研究人员在选择研究方向和设计网络架构等方面都有一定的参考价值。关键词:注视点渲染;深度学习;实时渲染;注视点预测;图像补全;超分辨率;光路追踪降噪385|4230|0更新时间:2024-10-23
摘要:在大型高分辨显示器和头戴式显式设备中实现实时、逼真的渲染仍然是计算机图形学面临的主要挑战之一。注视点渲染(foveated rendering)利用人类视觉系统的局限性,根据注视点调整图像渲染质量,从而在不损失用户感知质量的前提下大大提高渲染速度。随着深度学习方法在渲染领域的广泛应用,涌现出大量基于深度学习的注视点渲染新方法。本文从深度学习的角度对注视点渲染领域的最新方法进行综述。首先,概述了人类视觉感知的背景知识。接着,简要介绍了注视点渲染中最具代表性的非深度学习方法,包括自适应分辨率、几何简化、着色简化和硬件实现,并总结了这些方法的优缺点。随后,描述了文中用于评估深度学习不同方法所使用的评估准则,包括常用的注视点渲染图像的评估指标和注视点预测评估指标。接下来,将注视点渲染中的深度学习方法细分为超分辨率、降噪、补全、图像合成、注视点预测和图像应用,对它们进行详细概述和总结。最后,提出了深度学习方法目前面临的问题和挑战。通过对注视点渲染领域的深度学习方法的讨论,可以更详细地展示深度学习在注视点渲染中的研究前景和发展方向,对后续研究人员在选择研究方向和设计网络架构等方面都有一定的参考价值。关键词:注视点渲染;深度学习;实时渲染;注视点预测;图像补全;超分辨率;光路追踪降噪385|4230|0更新时间:2024-10-23 -
 摘要:目的针对现有无参考点云质量评估方法需要将点云预处理为二维投影或其他形式导致引入额外噪声、限制空间上下文等问题,提出了一种基于邻域信息嵌入变换模块和点云级联注意力模块的无参考点云质量评估方法。方法将点云样本整体作为输入,减轻预处理引入的失真。使用稀疏卷积搭建U型主干网络提取多尺度特征,邻域信息嵌入变换模块逐点学习提取特征,点云级联注意力模块增强小尺度特征,提高特征信息的可辨识性,最后逐步聚合多尺度特征信息形成特征向量,经全局自适应池化和回归函数进行回归预测,得到失真点云质量分数。结果实验在2个数据集上与现有的12种代表性点云质量评估方法进行了比较,在SJTU-PCQA(Shanghai Jiao Tong University subjective point cloud quality assessment)数据集中,相比于性能第2的模型,PLCC(Pearson linear correlation coefficient)值提高了8.7%,SROCC(Spearman rank-order coefficient correlation)值提高了0.39%;在WPC(waterloo point cloud)数据集中,相比于性能第2的模型,PLCC值提高了4.9%,SROCC值提高了3.0%。结论所提出的基于邻域信息嵌入变换和级联注意力的无参考点云质量评估方法,提高了可辨识特征提取能力,使点云质量评估结果更加准确。关键词:三维质量评估;点云;无参考;邻域信息;级联注意力328|617|0更新时间:2024-10-23
摘要:目的针对现有无参考点云质量评估方法需要将点云预处理为二维投影或其他形式导致引入额外噪声、限制空间上下文等问题,提出了一种基于邻域信息嵌入变换模块和点云级联注意力模块的无参考点云质量评估方法。方法将点云样本整体作为输入,减轻预处理引入的失真。使用稀疏卷积搭建U型主干网络提取多尺度特征,邻域信息嵌入变换模块逐点学习提取特征,点云级联注意力模块增强小尺度特征,提高特征信息的可辨识性,最后逐步聚合多尺度特征信息形成特征向量,经全局自适应池化和回归函数进行回归预测,得到失真点云质量分数。结果实验在2个数据集上与现有的12种代表性点云质量评估方法进行了比较,在SJTU-PCQA(Shanghai Jiao Tong University subjective point cloud quality assessment)数据集中,相比于性能第2的模型,PLCC(Pearson linear correlation coefficient)值提高了8.7%,SROCC(Spearman rank-order coefficient correlation)值提高了0.39%;在WPC(waterloo point cloud)数据集中,相比于性能第2的模型,PLCC值提高了4.9%,SROCC值提高了3.0%。结论所提出的基于邻域信息嵌入变换和级联注意力的无参考点云质量评估方法,提高了可辨识特征提取能力,使点云质量评估结果更加准确。关键词:三维质量评估;点云;无参考;邻域信息;级联注意力328|617|0更新时间:2024-10-23 -
 摘要:目的全局式从运动恢复结构(structure from motion, SfM)通过运动平均一次性恢复所有相机的绝对位姿,效率相对较高。运动平均中的平移平均主要负责解算相机在世界坐标系下的绝对位置,其求解过程因尺度歧义性、估计敏感性和求解不确定性的影响而较为困难。本文提出了一种基于增量尺度估计的平移平均方法,在消除尺度歧义性的同时提升了求解鲁棒性与准确性。方法本文将平移平均问题解耦为3个子问题:1)局部绝对尺度的增量式估计;2)全局绝对尺度的增量式估计;3)基于
摘要:目的全局式从运动恢复结构(structure from motion, SfM)通过运动平均一次性恢复所有相机的绝对位姿,效率相对较高。运动平均中的平移平均主要负责解算相机在世界坐标系下的绝对位置,其求解过程因尺度歧义性、估计敏感性和求解不确定性的影响而较为困难。本文提出了一种基于增量尺度估计的平移平均方法,在消除尺度歧义性的同时提升了求解鲁棒性与准确性。方法本文将平移平均问题解耦为3个子问题:1)局部绝对尺度的增量式估计;2)全局绝对尺度的增量式估计;3)基于 -
 摘要:目的混合现实技术通过混合现实场景和虚拟场景,为飞行模拟器提供了沉浸式体验。由于现实场景和虚拟场景的光照条件不一致,混合结果往往使用户产生较强的不协调感,从而降低体验沉浸感。本文使用虚拟场景的光照条件对机舱现实图像场景进行重光照,解决光照不一致问题。方法受计算机图形学重要的渲染方法——预计算辐射传输法的启发,首次提出一种基于辐射传输函数估计的神经重光照方法。首先使用卷积神经网络估计输入图像中每个渲染点的辐射传输函数在球谐函数上的系数形式表达,同时将虚拟环境中提供光照信息的环境光贴图投影到球谐函数上,最后将对应球谐系数向量进行点乘,获得重光照渲染结果。结果目视评测,生成的重光照图像与目标光照条件匹配程度良好,同时保留原图中细节,未出现伪影等异常渲染结果。以本文生成的重光照数据集为基准进行测试,本文方法生成结果峰值信噪比达到28.48 dB,比相似方法高出7.5%。结论成功在多款战斗机模型中应用了上述方法,可以根据给定虚拟飞行场景中的光照条件,对现实机舱内部图像进行重光照,实现机舱内外图像光照条件一致,提升了应用混合现实的飞行模拟器的用户沉浸感。关键词:重光照;神经渲染方法;辐射传输函数;混合现实(MR);飞行模拟器246|816|0更新时间:2024-10-23
摘要:目的混合现实技术通过混合现实场景和虚拟场景,为飞行模拟器提供了沉浸式体验。由于现实场景和虚拟场景的光照条件不一致,混合结果往往使用户产生较强的不协调感,从而降低体验沉浸感。本文使用虚拟场景的光照条件对机舱现实图像场景进行重光照,解决光照不一致问题。方法受计算机图形学重要的渲染方法——预计算辐射传输法的启发,首次提出一种基于辐射传输函数估计的神经重光照方法。首先使用卷积神经网络估计输入图像中每个渲染点的辐射传输函数在球谐函数上的系数形式表达,同时将虚拟环境中提供光照信息的环境光贴图投影到球谐函数上,最后将对应球谐系数向量进行点乘,获得重光照渲染结果。结果目视评测,生成的重光照图像与目标光照条件匹配程度良好,同时保留原图中细节,未出现伪影等异常渲染结果。以本文生成的重光照数据集为基准进行测试,本文方法生成结果峰值信噪比达到28.48 dB,比相似方法高出7.5%。结论成功在多款战斗机模型中应用了上述方法,可以根据给定虚拟飞行场景中的光照条件,对现实机舱内部图像进行重光照,实现机舱内外图像光照条件一致,提升了应用混合现实的飞行模拟器的用户沉浸感。关键词:重光照;神经渲染方法;辐射传输函数;混合现实(MR);飞行模拟器246|816|0更新时间:2024-10-23 -
 摘要:目的超声波空中触觉反馈技术为虚拟现实、混合现实提供非接触、无约束的触觉体验,是混合现实领域触觉呈现的主要途径。使用传统调制方法对多点图形进行聚焦呈现时,在每个调制周期内只进行单点聚焦,发射阵列的使用率较低,聚焦过程中产生噪声较大。针对现有调制方法的不足之处,提出了一种新型时空调制方法来提高阵列利用率并降低聚焦时产生的噪声。方法首先,根据所需呈现图形获取多个焦点的位置数据,计算每个焦点聚焦时发射器所需延时时间并进行储存;其次,将调制信号的周期按聚焦点个数进行平均分配,并生成超声发射器驱动信号;最后,将驱动信号发送至延时模块,并在调制信号周期的不同时间片内,将各聚焦点的延时数据送入,实现多点聚焦触觉同步的效果。结果通过实验对新型调制方法进行测试,在进行占空比为10%和20%的两点聚焦时,相比于传统调制方法,调制噪声分别降低了8.4%和13%,聚焦功耗提高了80%和86%;在进行占空比为10%和20%的四点聚焦时,相比于传统调制方法,调制噪声降低了6.3%和10.1%,聚焦功耗分别提高了60%和100%。在主观图形识别实验中,三角形、矩形、圆形的识别率分别提升了25%、 19%、35%。实验结果表明新型调制方法降低了聚焦噪声,提高了阵列利用率以及对呈现图形的识别率。结论本文所提出的新型时空调制方法有效减小了聚焦噪声,提供了更好的触觉图形反馈效果。关键词:图形呈现;时空调制;超声波反馈;空中触觉;多点触觉270|922|0更新时间:2024-10-23
摘要:目的超声波空中触觉反馈技术为虚拟现实、混合现实提供非接触、无约束的触觉体验,是混合现实领域触觉呈现的主要途径。使用传统调制方法对多点图形进行聚焦呈现时,在每个调制周期内只进行单点聚焦,发射阵列的使用率较低,聚焦过程中产生噪声较大。针对现有调制方法的不足之处,提出了一种新型时空调制方法来提高阵列利用率并降低聚焦时产生的噪声。方法首先,根据所需呈现图形获取多个焦点的位置数据,计算每个焦点聚焦时发射器所需延时时间并进行储存;其次,将调制信号的周期按聚焦点个数进行平均分配,并生成超声发射器驱动信号;最后,将驱动信号发送至延时模块,并在调制信号周期的不同时间片内,将各聚焦点的延时数据送入,实现多点聚焦触觉同步的效果。结果通过实验对新型调制方法进行测试,在进行占空比为10%和20%的两点聚焦时,相比于传统调制方法,调制噪声分别降低了8.4%和13%,聚焦功耗提高了80%和86%;在进行占空比为10%和20%的四点聚焦时,相比于传统调制方法,调制噪声降低了6.3%和10.1%,聚焦功耗分别提高了60%和100%。在主观图形识别实验中,三角形、矩形、圆形的识别率分别提升了25%、 19%、35%。实验结果表明新型调制方法降低了聚焦噪声,提高了阵列利用率以及对呈现图形的识别率。结论本文所提出的新型时空调制方法有效减小了聚焦噪声,提供了更好的触觉图形反馈效果。关键词:图形呈现;时空调制;超声波反馈;空中触觉;多点触觉270|922|0更新时间:2024-10-23
混合现实
-
 摘要:目的基于深度学习的端到端单图像去模糊方法已取得了优秀成果。但大多数网络中的构建块仅专注于提取局部特征,而在建模远距离像素依赖关系方面表现出局限性。为解决这一问题,提出了一种为网络引入局部特征和非局部特征的方法。方法采用现有的优秀构建块提取局部特征,将大窗口的Transformer块划分为更小的不重叠图像块,对每个图像块仅采样一个最大值点参与自注意力运算,在不占用过多计算资源的情况下提取非局部特征。最后将两个模块结合应用,在块内耦合局部信息和非局部信息,从而有效捕捉更丰富的特征信息。结果实验表明,相比于仅能提取局部信息的模块,提出的模块在峰值信噪比(peak signal-to-noise ratio, PSNR)指标上的提升不少于1.3 dB。此外,设计两个局部与非局部特征耦合的图像复原网络,分别运用在单图像去运动模糊和去散焦模糊任务上,与Uformer(a general U-shaped Transformer for image restoration)相比,在去运动模糊测试集GoPro(deep multi-scale convolutional neural network for dynamic scene deblurring)和HIDE(human-aware motion deblurring)上的平均PSNR分别提高了0.29 dB和0.25 dB,且模型的浮点数更低。在去散焦模糊测试集DPD(defocus deblurring using dual-pixel data)上,平均PSNR提高了0.42 dB。结论本文方法在块内成功引入非局部信息,使得模型能够同时捕捉局部特征和非局部特征,获得更多的特征表示,提升了去模糊网络的性能。同时,恢复图像也具有更清楚的边缘,更接近真实图像。关键词:运动模糊;散焦模糊;自注意力;非局部特征;融合网络634|961|0更新时间:2024-10-23
摘要:目的基于深度学习的端到端单图像去模糊方法已取得了优秀成果。但大多数网络中的构建块仅专注于提取局部特征,而在建模远距离像素依赖关系方面表现出局限性。为解决这一问题,提出了一种为网络引入局部特征和非局部特征的方法。方法采用现有的优秀构建块提取局部特征,将大窗口的Transformer块划分为更小的不重叠图像块,对每个图像块仅采样一个最大值点参与自注意力运算,在不占用过多计算资源的情况下提取非局部特征。最后将两个模块结合应用,在块内耦合局部信息和非局部信息,从而有效捕捉更丰富的特征信息。结果实验表明,相比于仅能提取局部信息的模块,提出的模块在峰值信噪比(peak signal-to-noise ratio, PSNR)指标上的提升不少于1.3 dB。此外,设计两个局部与非局部特征耦合的图像复原网络,分别运用在单图像去运动模糊和去散焦模糊任务上,与Uformer(a general U-shaped Transformer for image restoration)相比,在去运动模糊测试集GoPro(deep multi-scale convolutional neural network for dynamic scene deblurring)和HIDE(human-aware motion deblurring)上的平均PSNR分别提高了0.29 dB和0.25 dB,且模型的浮点数更低。在去散焦模糊测试集DPD(defocus deblurring using dual-pixel data)上,平均PSNR提高了0.42 dB。结论本文方法在块内成功引入非局部信息,使得模型能够同时捕捉局部特征和非局部特征,获得更多的特征表示,提升了去模糊网络的性能。同时,恢复图像也具有更清楚的边缘,更接近真实图像。关键词:运动模糊;散焦模糊;自注意力;非局部特征;融合网络634|961|0更新时间:2024-10-23 -
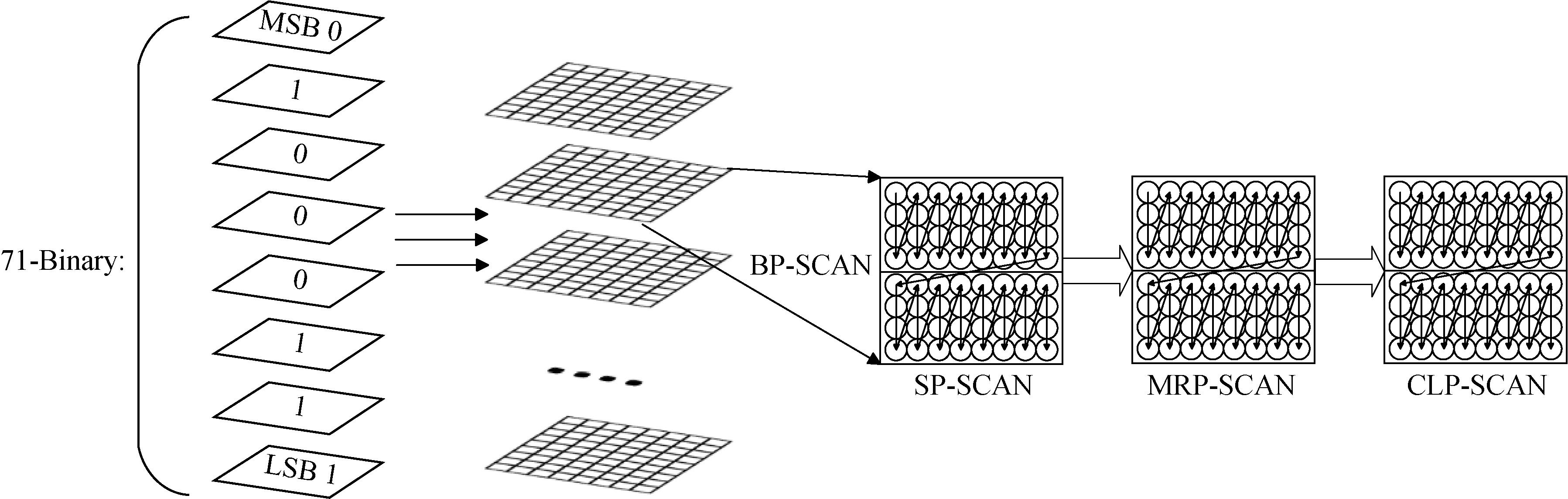 摘要:目的EBCOT(embedded block coding with optimized truncation)优化截取内嵌码块编码的结果对JPEG2000的压缩质量产生直接影响,且EBCOT编码在整个JPEG2000压缩过程中占据较长时间。此外,由于该算法的复杂性较高,在硬件实现时需要考虑其对硬件资源的使用率。对此,提出了一种高效的EBCOT编码VLSI(very large scale integration circuit)结构。方法首先,EBCOT编码分为两部分:Tier1编码与Tier2编码。针对影响编码速度的Tier1编码部分,设计了一种全新的编码窗口结构,即多位平面循环编码(multi-bitplanes cyclic encoding, MBCE),其通过预测的方式对连续的位平面进行编码;针对Tier2编码部分中的通道失真误差计算,设计了与Tier1编码并行的流水线计算结构。结果采用Verilog语言对该VLSI结构进行描述,将FPGA(field programmable gate array)作为实验验证平台,从多个角度与现有的EBCOT优化VLSI结构进行比较。从编码效率上来看,MBCE结构在实现全通道并行的基础上,编码效率有明显的提升、所占用的硬件资源较少、工作频率较高。在同一压缩条件下,使用MBCE结构与以JPEG2000为标准的图像压缩软件对同一幅512 × 512像素的8位灰度图像进行压缩对比,峰值信噪比(peak signal-to-noise ratio,PSNR)的误差不超过0.05 dB,在xc4vlx25型号FPGA上其工作频率可以达到193.1 MHz,每秒能够处理370帧图像。结论本文提出的全通道MBCE的EBCOT编码VLSI结构,具有资源占用率低、编码周期短、压缩质量好的特点。关键词:EBCOT编码;多位平面循环编码(MBCE);通道失真计算;通道并行;VLSI结构243|456|0更新时间:2024-10-23
摘要:目的EBCOT(embedded block coding with optimized truncation)优化截取内嵌码块编码的结果对JPEG2000的压缩质量产生直接影响,且EBCOT编码在整个JPEG2000压缩过程中占据较长时间。此外,由于该算法的复杂性较高,在硬件实现时需要考虑其对硬件资源的使用率。对此,提出了一种高效的EBCOT编码VLSI(very large scale integration circuit)结构。方法首先,EBCOT编码分为两部分:Tier1编码与Tier2编码。针对影响编码速度的Tier1编码部分,设计了一种全新的编码窗口结构,即多位平面循环编码(multi-bitplanes cyclic encoding, MBCE),其通过预测的方式对连续的位平面进行编码;针对Tier2编码部分中的通道失真误差计算,设计了与Tier1编码并行的流水线计算结构。结果采用Verilog语言对该VLSI结构进行描述,将FPGA(field programmable gate array)作为实验验证平台,从多个角度与现有的EBCOT优化VLSI结构进行比较。从编码效率上来看,MBCE结构在实现全通道并行的基础上,编码效率有明显的提升、所占用的硬件资源较少、工作频率较高。在同一压缩条件下,使用MBCE结构与以JPEG2000为标准的图像压缩软件对同一幅512 × 512像素的8位灰度图像进行压缩对比,峰值信噪比(peak signal-to-noise ratio,PSNR)的误差不超过0.05 dB,在xc4vlx25型号FPGA上其工作频率可以达到193.1 MHz,每秒能够处理370帧图像。结论本文提出的全通道MBCE的EBCOT编码VLSI结构,具有资源占用率低、编码周期短、压缩质量好的特点。关键词:EBCOT编码;多位平面循环编码(MBCE);通道失真计算;通道并行;VLSI结构243|456|0更新时间:2024-10-23
图像处理和编码
-
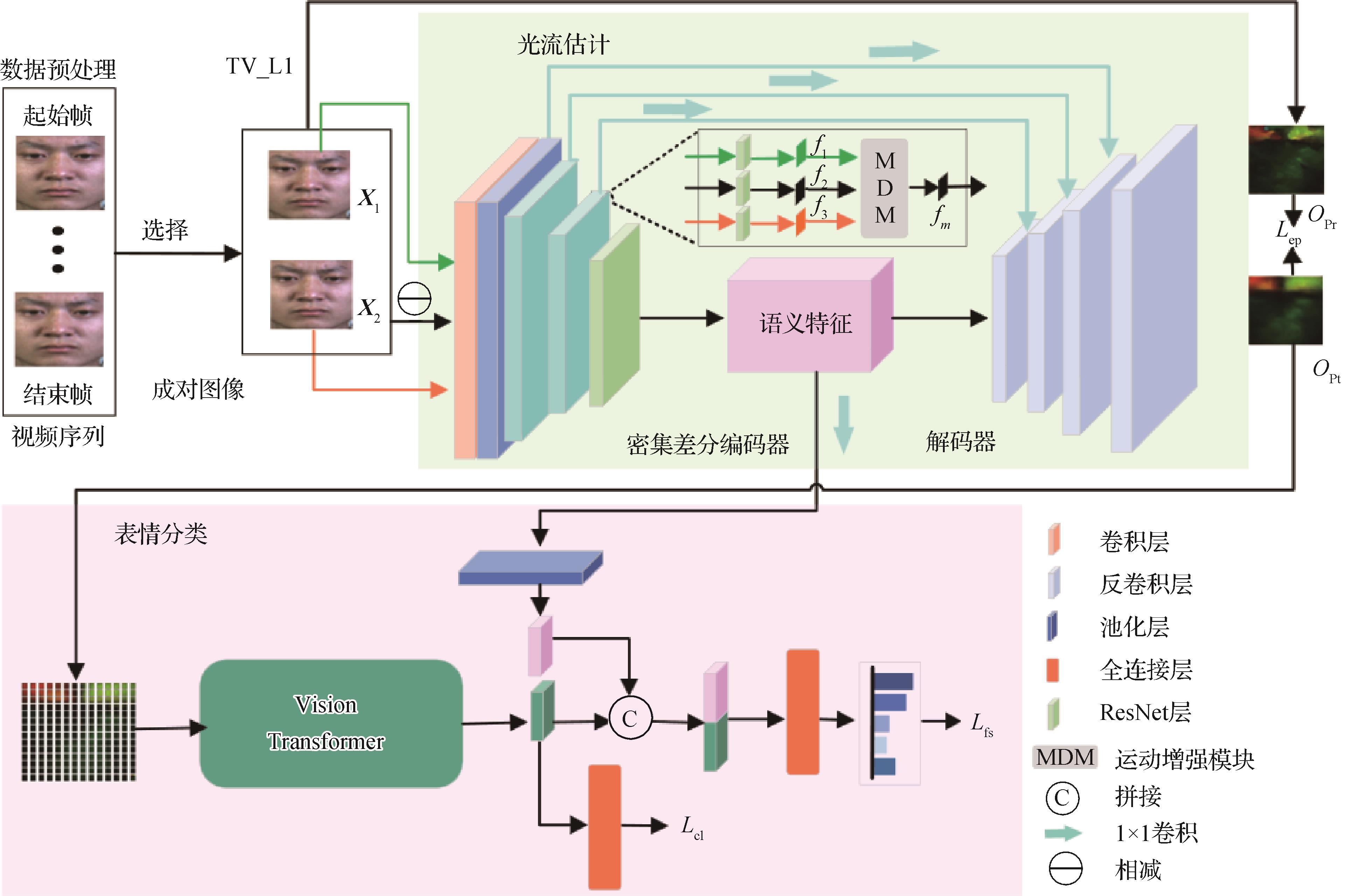 摘要:目的微表情识别旨在从面部肌肉应激性运动中自动分析和鉴别研究对象的情感类别,其在谎言检测、心理诊断等方面具有重要应用价值。然而,当前微表情识别方法通常依赖离线光流估计,导致微表情特征表征能力不足。针对该问题,提出了一种基于自适应光流估计的微表情识别模型(adaptive micro-expression recognition, AdaMER)。方法AdaMER并行联立实现光流估计和微表情分类两个任务自适应学习微表情相关的运动特征。首先,提出密集差分编码—解码器以提取多层次面部位移信息,实现自适应光流估计;然后,借助视觉Transformer挖掘重建光流蕴含的微表情判别性信息;最后,融合面部位移微表情语义信息与微表情判别信息进行微表情分类。结果在由SMIC(spontaneous micro-expression recognition)、SAMM(spontaneous micro-facial movement dataset)和CASME II(the Chinese Academy of Sciences micro-expression)构建的复合微表情数据集上进行大量实验,结果显示本文方法UF1(unweighted F1-score)和UAR(unweighted average recall)分别达到了82.89%和85.95%,相比于最新方法FRL-DGT(feature representation learning with adaptive displacement generation and Transformer fusion)分别提升了1.77%和4.85%。结论本文方法融合了自适应光流估计与微表情分类两个任务,一方面以端到端的方式实现自适应光流估计以感知面部细微运动,提高细微表情描述能力;另一方面,充分挖掘微表情判别信息,提升微表情识别性能。关键词:微表情识别;自适应光流估计;运动特征;差分编码;特征融合540|925|0更新时间:2024-10-23
摘要:目的微表情识别旨在从面部肌肉应激性运动中自动分析和鉴别研究对象的情感类别,其在谎言检测、心理诊断等方面具有重要应用价值。然而,当前微表情识别方法通常依赖离线光流估计,导致微表情特征表征能力不足。针对该问题,提出了一种基于自适应光流估计的微表情识别模型(adaptive micro-expression recognition, AdaMER)。方法AdaMER并行联立实现光流估计和微表情分类两个任务自适应学习微表情相关的运动特征。首先,提出密集差分编码—解码器以提取多层次面部位移信息,实现自适应光流估计;然后,借助视觉Transformer挖掘重建光流蕴含的微表情判别性信息;最后,融合面部位移微表情语义信息与微表情判别信息进行微表情分类。结果在由SMIC(spontaneous micro-expression recognition)、SAMM(spontaneous micro-facial movement dataset)和CASME II(the Chinese Academy of Sciences micro-expression)构建的复合微表情数据集上进行大量实验,结果显示本文方法UF1(unweighted F1-score)和UAR(unweighted average recall)分别达到了82.89%和85.95%,相比于最新方法FRL-DGT(feature representation learning with adaptive displacement generation and Transformer fusion)分别提升了1.77%和4.85%。结论本文方法融合了自适应光流估计与微表情分类两个任务,一方面以端到端的方式实现自适应光流估计以感知面部细微运动,提高细微表情描述能力;另一方面,充分挖掘微表情判别信息,提升微表情识别性能。关键词:微表情识别;自适应光流估计;运动特征;差分编码;特征融合540|925|0更新时间:2024-10-23 -
 摘要:目的工业产品表面的缺陷检测是保证其质量的重要环节。针对工业产品表面缺陷与背景相似度高、表面缺陷特征相似的问题,提出了一种差异化检测网络YOLO-Differ(you only look once-difference)。方法该网络以YOLOv5(you only look once version 5)为基础,利用离散余弦变换算法和自注意力机制提取和增强频率特征,并通过融合频率特征,增大缺陷与背景特征之间的区分度;同时考虑到融合中存在的错位问题,设计自适应特征融合模块对齐并融合RGB特征和频率特征。其次,在网络的检测模块后新增细粒度分类分支,将视觉变换器(vision Transformer,ViT)作为该分支中的校正分类器,专注于提取和识别缺陷的微小特征差异,以应对不同缺陷特征细微差异的挑战。结果实验在3个数据集上与7种目标检测模型进行了对比,YOLO-Differ模型均取得了最优结果,与其他模型相比,平均准确率均值(mean average precision,mAP)分别提升了3.6%、2.4%和0.4%以上。结论YOLO-Differ模型与同类模型相比,具有更高的检测精度和更强的通用性。关键词:表面缺陷检测;相似性;频率特征;细粒度分类;通用性377|2041|0更新时间:2024-10-23
摘要:目的工业产品表面的缺陷检测是保证其质量的重要环节。针对工业产品表面缺陷与背景相似度高、表面缺陷特征相似的问题,提出了一种差异化检测网络YOLO-Differ(you only look once-difference)。方法该网络以YOLOv5(you only look once version 5)为基础,利用离散余弦变换算法和自注意力机制提取和增强频率特征,并通过融合频率特征,增大缺陷与背景特征之间的区分度;同时考虑到融合中存在的错位问题,设计自适应特征融合模块对齐并融合RGB特征和频率特征。其次,在网络的检测模块后新增细粒度分类分支,将视觉变换器(vision Transformer,ViT)作为该分支中的校正分类器,专注于提取和识别缺陷的微小特征差异,以应对不同缺陷特征细微差异的挑战。结果实验在3个数据集上与7种目标检测模型进行了对比,YOLO-Differ模型均取得了最优结果,与其他模型相比,平均准确率均值(mean average precision,mAP)分别提升了3.6%、2.4%和0.4%以上。结论YOLO-Differ模型与同类模型相比,具有更高的检测精度和更强的通用性。关键词:表面缺陷检测;相似性;频率特征;细粒度分类;通用性377|2041|0更新时间:2024-10-23
图像分析和识别
-
 摘要:目的快速检测工业场景中的文本,可以提高生产效率、降低成本,然而数据的标注耗时耗力,鲜有标注信息可用,针对目前方法在应用到工业数据时存在伪标签质量低和域差距较大等问题,本文提出了一种结合文本自训练和对抗学习的领域自适应工业场景文本检测方法。方法首先,针对伪标签质量低的问题,采用教师学生框架进行文本自训练。教师和学生模型应用数据增强和相互学习缓解域偏移,提高伪标签的质量;其次,针对域差距,提出图像级和实例级对抗学习模块来对齐源域和目标域的特征分布,使网络学习域不变特征;最后,在两个对抗学习模块之间使用一致性正则化进一步缓解域差距,提高模型的域适应能力。结果实验证明,本文的方法在工业铭牌数据集的精确率、召回率和F1值分别达到96.2%、95.0%和95.6%,较基线模型分别提高了10%、15.3%和12.8%。同时在ICDAR15和MSRA-TD500数据集上也表现出良好性能,与当前先进的方法相比,F1值分别提高0.9%和3.1%。此外,本文的方法在应用到EAST(efficient and accurate scene text detector)文本检测模型后,铭牌数据集的各指标分别提升5%,11.8%和9.5%。结论本文提出的方法成功缓解了源域与目标域数据之间的差距,显著提高了模型的泛化能力,并且具有良好的通用性,同时模型推理阶段不会增加计算成本。关键词:场景文本检测;领域自适应;文本自训练;特征对抗学习;一致性正则化328|618|0更新时间:2024-10-23
摘要:目的快速检测工业场景中的文本,可以提高生产效率、降低成本,然而数据的标注耗时耗力,鲜有标注信息可用,针对目前方法在应用到工业数据时存在伪标签质量低和域差距较大等问题,本文提出了一种结合文本自训练和对抗学习的领域自适应工业场景文本检测方法。方法首先,针对伪标签质量低的问题,采用教师学生框架进行文本自训练。教师和学生模型应用数据增强和相互学习缓解域偏移,提高伪标签的质量;其次,针对域差距,提出图像级和实例级对抗学习模块来对齐源域和目标域的特征分布,使网络学习域不变特征;最后,在两个对抗学习模块之间使用一致性正则化进一步缓解域差距,提高模型的域适应能力。结果实验证明,本文的方法在工业铭牌数据集的精确率、召回率和F1值分别达到96.2%、95.0%和95.6%,较基线模型分别提高了10%、15.3%和12.8%。同时在ICDAR15和MSRA-TD500数据集上也表现出良好性能,与当前先进的方法相比,F1值分别提高0.9%和3.1%。此外,本文的方法在应用到EAST(efficient and accurate scene text detector)文本检测模型后,铭牌数据集的各指标分别提升5%,11.8%和9.5%。结论本文提出的方法成功缓解了源域与目标域数据之间的差距,显著提高了模型的泛化能力,并且具有良好的通用性,同时模型推理阶段不会增加计算成本。关键词:场景文本检测;领域自适应;文本自训练;特征对抗学习;一致性正则化328|618|0更新时间:2024-10-23 -
 摘要:目的船名文本信息是船舶身份识别的核心要素。真实场景船舶影像中文本区域尺度不一导致船名文本检测存在漏检等问题。同时,现有自然场景文本检测算法难以排除背景文本、图案等因素对船名检测任务的干扰。因此,针对以上问题提出一种融合场景先验的船名检测方法。方法首先,依据船首与船名目标关联性,提出一个基于先验损失的区域监督模块,以约束模型关注船名文本区域特征。然后,为了提高文本区域细粒度,提出一个基于非对称卷积的船名区域定位模块,增强文本区域边缘信息,进一步提高船名检测的召回率。结果本文收集、标注并公开发布了一个真实场景船名文本检测数据集CBWLZ2023进行实验验证,并与最新的8种通用自然场景文本检测方法进行比较。本文算法在船名文本检测任务上取得了94.2%的F1值,相比于性能第2的模型,F1值提高了2.3%;相比于基线模型,F1值提高了2.8%。同时在CBWLZ2023数据集中进行了参数分析实验及消融实验以验证算法各模块的有效性。实验结果证明提出的算法能准确获取边界清晰的文本区域,改善了船名文本检测的效果。结论本文提出的融合场景先验的船名检测模型,可以解决船名文本尺度不一、背景文本干扰带来的问题,在检测精度上超过了现有的场景文本检测算法,具有有效性与先进性。CBWLZ2023可由https://aistudio.baidu.com/aistudio/datasetdetail/224137获取。关键词:船名文本检测;场景先验损失;区域监督;特征增强;非对称卷积463|997|0更新时间:2024-10-23
摘要:目的船名文本信息是船舶身份识别的核心要素。真实场景船舶影像中文本区域尺度不一导致船名文本检测存在漏检等问题。同时,现有自然场景文本检测算法难以排除背景文本、图案等因素对船名检测任务的干扰。因此,针对以上问题提出一种融合场景先验的船名检测方法。方法首先,依据船首与船名目标关联性,提出一个基于先验损失的区域监督模块,以约束模型关注船名文本区域特征。然后,为了提高文本区域细粒度,提出一个基于非对称卷积的船名区域定位模块,增强文本区域边缘信息,进一步提高船名检测的召回率。结果本文收集、标注并公开发布了一个真实场景船名文本检测数据集CBWLZ2023进行实验验证,并与最新的8种通用自然场景文本检测方法进行比较。本文算法在船名文本检测任务上取得了94.2%的F1值,相比于性能第2的模型,F1值提高了2.3%;相比于基线模型,F1值提高了2.8%。同时在CBWLZ2023数据集中进行了参数分析实验及消融实验以验证算法各模块的有效性。实验结果证明提出的算法能准确获取边界清晰的文本区域,改善了船名文本检测的效果。结论本文提出的融合场景先验的船名检测模型,可以解决船名文本尺度不一、背景文本干扰带来的问题,在检测精度上超过了现有的场景文本检测算法,具有有效性与先进性。CBWLZ2023可由https://aistudio.baidu.com/aistudio/datasetdetail/224137获取。关键词:船名文本检测;场景先验损失;区域监督;特征增强;非对称卷积463|997|0更新时间:2024-10-23 -
 摘要:目的三维人体姿态估计是计算机视觉的研究热点之一,当前大多数方法直接从视频或二维坐标点回归人体三维关节坐标,忽略了关节旋转角的估计。但是,人体关节旋转角对于一些虚拟现实、计算机动画应用至关重要。为此,本文提出一种能同时估计三维人体坐标及旋转角的注意力融合网络。方法首先应用骨骼长度网络和骨骼方向网络分别从2D人体姿态序列中估计出人体骨骼长度和骨骼方向,并据此计算出初步的三维人体坐标,然后将初步的三维坐标输入关节旋转角估计网络得到关节旋转角,并应用前向运动学(forward kinematics,FK)层计算与关节旋转角对应的三维人体坐标。但由于网络模块的误差累积,与关节旋转角对应的三维人体坐标比初步的三维坐标精度有所降低,但是FK层输出的三维坐标具有更稳定的骨架结构。因此,为了综合这两种三维坐标序列的优势,最后通过注意力融合模块将初步的三维坐标及与关节旋转角对应的三维人体坐标融合为最终的三维关节坐标。这种分步估计的人体姿态估计算法,能够对估计的中间状态加以约束,并且使用注意力融合机制综合了高精度和骨骼稳定性的特点,使得最终结果的精度得到提升。另外,设计了一种专门的根关节处理模块,能够输出更高精度的根关节坐标,从而进一步提升三维人体坐标的精度和平滑性。结果实验在Human3.6M数据集上与对比方法比较平均关节位置误差(mean per joint position error,MPJPE),结果表明,与能够同时计算关节点坐标和旋转角的工作相比,本文方法取得了最好的精度。结论本文提出的方法能够同时从视频中估计人体关节坐标和关节旋转角度,并且得到的人体关节坐标比现有方法具有更高的精度。关键词:人体姿态估计;关节坐标;关节旋转角;注意力融合;分步估计405|696|0更新时间:2024-10-23
摘要:目的三维人体姿态估计是计算机视觉的研究热点之一,当前大多数方法直接从视频或二维坐标点回归人体三维关节坐标,忽略了关节旋转角的估计。但是,人体关节旋转角对于一些虚拟现实、计算机动画应用至关重要。为此,本文提出一种能同时估计三维人体坐标及旋转角的注意力融合网络。方法首先应用骨骼长度网络和骨骼方向网络分别从2D人体姿态序列中估计出人体骨骼长度和骨骼方向,并据此计算出初步的三维人体坐标,然后将初步的三维坐标输入关节旋转角估计网络得到关节旋转角,并应用前向运动学(forward kinematics,FK)层计算与关节旋转角对应的三维人体坐标。但由于网络模块的误差累积,与关节旋转角对应的三维人体坐标比初步的三维坐标精度有所降低,但是FK层输出的三维坐标具有更稳定的骨架结构。因此,为了综合这两种三维坐标序列的优势,最后通过注意力融合模块将初步的三维坐标及与关节旋转角对应的三维人体坐标融合为最终的三维关节坐标。这种分步估计的人体姿态估计算法,能够对估计的中间状态加以约束,并且使用注意力融合机制综合了高精度和骨骼稳定性的特点,使得最终结果的精度得到提升。另外,设计了一种专门的根关节处理模块,能够输出更高精度的根关节坐标,从而进一步提升三维人体坐标的精度和平滑性。结果实验在Human3.6M数据集上与对比方法比较平均关节位置误差(mean per joint position error,MPJPE),结果表明,与能够同时计算关节点坐标和旋转角的工作相比,本文方法取得了最好的精度。结论本文提出的方法能够同时从视频中估计人体关节坐标和关节旋转角度,并且得到的人体关节坐标比现有方法具有更高的精度。关键词:人体姿态估计;关节坐标;关节旋转角;注意力融合;分步估计405|696|0更新时间:2024-10-23 -
 摘要:目的柑橘是我国最常见的水果之一,目前多以人工采摘为主,成本高、效率低等问题严重制约规模化生产,因此柑橘自动采摘成为近年的研究热点。但是,柑橘生长环境复杂、枝条形态各异、枝叶和果实互遮挡严重,如何精准实时地定位采摘点成为自动采摘的关键。通过构建级联混合网络模型,提出了一种通用且高效的柑橘采摘点自动精准定位方法。方法构建团簇框生成模型和枝条稀疏实例分割模型,对两者进行级联混合实现实时柑橘采摘点定位。首先,构建柑橘果实检测网络,提出团簇框生成模型,该模型通过特征提取、果实检测框生成和DBSCAN(density-based spatial clustering of applications with noise)果实密度聚类,实时地生成图像内果实数目最多的团簇框坐标;然后,提出融合亮度先验的枝条稀疏分割模型,该模型以团簇框内的图像作为输入,有效降低背景枝条的干扰,通过融合亮度先验的稀疏实例激活图,实时地分割出与果实相连接枝条实例;最后基于分割结果搜索果实采摘点定位坐标。结果经过长时间户外采集制作了柑橘果实检测数据集CFDD(citrus fruit detection dataset)和柑橘枝条分割数据集CBSD(citrus branch segmentation dataset)。这两个数据集由成熟果实、未成熟果实组成,包含晴天、阴天、顺光和逆光等挑战,总共37 000幅图像。在该数据集上本文方法的采摘点定位精准度达到了95.77%,帧率(frames per second,FPS)达到了28.21帧/s。结论本文方法在果实采摘点定位方面取得较好进展,能够快速且准确地获取柑橘采摘点,并且提供配套的机械臂采摘设备可供该采摘点定位算法的落地使用,为柑橘产业发展提供有力支持。关键词:采摘机器人;采摘点定位方法;团簇框生成器;亮度先验;枝条稀疏分割模型368|1654|0更新时间:2024-10-23
摘要:目的柑橘是我国最常见的水果之一,目前多以人工采摘为主,成本高、效率低等问题严重制约规模化生产,因此柑橘自动采摘成为近年的研究热点。但是,柑橘生长环境复杂、枝条形态各异、枝叶和果实互遮挡严重,如何精准实时地定位采摘点成为自动采摘的关键。通过构建级联混合网络模型,提出了一种通用且高效的柑橘采摘点自动精准定位方法。方法构建团簇框生成模型和枝条稀疏实例分割模型,对两者进行级联混合实现实时柑橘采摘点定位。首先,构建柑橘果实检测网络,提出团簇框生成模型,该模型通过特征提取、果实检测框生成和DBSCAN(density-based spatial clustering of applications with noise)果实密度聚类,实时地生成图像内果实数目最多的团簇框坐标;然后,提出融合亮度先验的枝条稀疏分割模型,该模型以团簇框内的图像作为输入,有效降低背景枝条的干扰,通过融合亮度先验的稀疏实例激活图,实时地分割出与果实相连接枝条实例;最后基于分割结果搜索果实采摘点定位坐标。结果经过长时间户外采集制作了柑橘果实检测数据集CFDD(citrus fruit detection dataset)和柑橘枝条分割数据集CBSD(citrus branch segmentation dataset)。这两个数据集由成熟果实、未成熟果实组成,包含晴天、阴天、顺光和逆光等挑战,总共37 000幅图像。在该数据集上本文方法的采摘点定位精准度达到了95.77%,帧率(frames per second,FPS)达到了28.21帧/s。结论本文方法在果实采摘点定位方面取得较好进展,能够快速且准确地获取柑橘采摘点,并且提供配套的机械臂采摘设备可供该采摘点定位算法的落地使用,为柑橘产业发展提供有力支持。关键词:采摘机器人;采摘点定位方法;团簇框生成器;亮度先验;枝条稀疏分割模型368|1654|0更新时间:2024-10-23
图像理解和计算机视觉
-
 摘要:目的为了解决柔性体布料与复杂刚体模型的碰撞检测速率低与真实性差的问题,本文提出混合结构的层次包围盒法(bounding volume hierarchies, BVH)和快速构造OBB(oriented bounding box)包围盒法以及对被检测物体构造空间网格法来提高碰撞检测的时效性。方法首先构建适合柔性体布料的混合结构的层次包围盒树,顶层和底层分别使用结构简单的球形包围盒和AABB(aixe align bounding box)包围盒,中间层使用球形—AABB混合结构对碰撞对进行快速高效剔除。其次对复杂刚体模型使用三角形折叠法进行表面简化,用简化模型代替原复杂模型进行包围盒快速构建。最后构建空间网格,进行更精确的碰撞检测以及碰撞响应。结果实验结果表明,在相同场景情况下,本文方法与其他方法相比包围盒构建速度缩短了10%~18%,对复杂刚体模型构建的OBB包围盒紧密程度提升了8%~15%。包围盒剔除率在相同模型情况下比传统方法提升了8%~13%,整体碰撞检测耗时缩短了6%~13%。本文方法在速率和剔除率提升的情况下模拟的真实性也得到了保证。结论本文方法在检测速率和碰撞剔除率上都有所提升,能够在保证模拟真实的情况下缩短整体碰撞检测耗时,更适用于柔性体和刚体之间的碰撞检测。关键词:碰撞检测;布料模拟;混合层次包围盒;简化模型;空间网格338|791|0更新时间:2024-10-23
摘要:目的为了解决柔性体布料与复杂刚体模型的碰撞检测速率低与真实性差的问题,本文提出混合结构的层次包围盒法(bounding volume hierarchies, BVH)和快速构造OBB(oriented bounding box)包围盒法以及对被检测物体构造空间网格法来提高碰撞检测的时效性。方法首先构建适合柔性体布料的混合结构的层次包围盒树,顶层和底层分别使用结构简单的球形包围盒和AABB(aixe align bounding box)包围盒,中间层使用球形—AABB混合结构对碰撞对进行快速高效剔除。其次对复杂刚体模型使用三角形折叠法进行表面简化,用简化模型代替原复杂模型进行包围盒快速构建。最后构建空间网格,进行更精确的碰撞检测以及碰撞响应。结果实验结果表明,在相同场景情况下,本文方法与其他方法相比包围盒构建速度缩短了10%~18%,对复杂刚体模型构建的OBB包围盒紧密程度提升了8%~15%。包围盒剔除率在相同模型情况下比传统方法提升了8%~13%,整体碰撞检测耗时缩短了6%~13%。本文方法在速率和剔除率提升的情况下模拟的真实性也得到了保证。结论本文方法在检测速率和碰撞剔除率上都有所提升,能够在保证模拟真实的情况下缩短整体碰撞检测耗时,更适用于柔性体和刚体之间的碰撞检测。关键词:碰撞检测;布料模拟;混合层次包围盒;简化模型;空间网格338|791|0更新时间:2024-10-23
计算机图形学
-
 摘要:目的高质量的病理切片对人工诊断和计算机辅助诊断至关重要。当前基于图像块的伪影检测方法存在着计算资源消耗巨大以及伪影检测过程的完整性缺失问题。为此,本文提出了一种适用于低倍率病理全切片图像的伪影检测算法WRC_Net(window-row-col_net)。方法首先,将低倍率的全切片图像输入到ResNet50(residual neural network)网络中,以提取图像的低级特征。随后,这些低级特征被传入特征融合模块,用于聚合来自不同深度和方向的特征。此外,在特征提取模块中,引入了WRC模块,包括WRC注意力和多尺度扩张模块,其能够同时捕捉全局和局部信息,提取多尺度特征,从而增强了特征的表达能力。最后,将融合后的特征传入单一检测头,以获取最终的检测结果。结果在SPDPSD(Shanghai Pudong department of pathology slide dataset)和NCPDCSD(Ningbo clinical pathology diagnosis center slide dataset)两个数据集上,所提方法的平均精度(mean average precision,mAP)分别达到了63.1%和55.0%,与目前主流的目标检测算法相比具有一定竞争力。结论本文提出的病理切片伪影检测算法能够准确识别数字病理切片中的不同种类伪影,为病理图像质量评估提供了一种有效的技术解决方案。关键词:数字病理学;数字病理切片;伪影检测;多尺度;特征融合373|833|0更新时间:2024-10-23
摘要:目的高质量的病理切片对人工诊断和计算机辅助诊断至关重要。当前基于图像块的伪影检测方法存在着计算资源消耗巨大以及伪影检测过程的完整性缺失问题。为此,本文提出了一种适用于低倍率病理全切片图像的伪影检测算法WRC_Net(window-row-col_net)。方法首先,将低倍率的全切片图像输入到ResNet50(residual neural network)网络中,以提取图像的低级特征。随后,这些低级特征被传入特征融合模块,用于聚合来自不同深度和方向的特征。此外,在特征提取模块中,引入了WRC模块,包括WRC注意力和多尺度扩张模块,其能够同时捕捉全局和局部信息,提取多尺度特征,从而增强了特征的表达能力。最后,将融合后的特征传入单一检测头,以获取最终的检测结果。结果在SPDPSD(Shanghai Pudong department of pathology slide dataset)和NCPDCSD(Ningbo clinical pathology diagnosis center slide dataset)两个数据集上,所提方法的平均精度(mean average precision,mAP)分别达到了63.1%和55.0%,与目前主流的目标检测算法相比具有一定竞争力。结论本文提出的病理切片伪影检测算法能够准确识别数字病理切片中的不同种类伪影,为病理图像质量评估提供了一种有效的技术解决方案。关键词:数字病理学;数字病理切片;伪影检测;多尺度;特征融合373|833|0更新时间:2024-10-23
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0